
记一些运维实践
刚工作时候,有个大学生优选培训计划,当时导师是运维老司机,所以跟随着他捣鼓了一些运维方面的问题,想想也都是几年前的事了,以下这些实践都是从印象笔记迁移过来的,就当留作个纪念吧 ~
Oracle 11g 安装
什么?安装也要搬进来吗?是的,Oracle 的安装绝不简单,整个过程可以学到很多东西,关键点在于怎么去搜索和排错。
Oracle 具体安装步骤可以参照文档 👈
同时也记录下来操作过程中的一些命令 👈
ESXI 虚拟化平台
虚拟化,简单讲,就是可以实现将一台计算机虚拟化为若干台逻辑计算机,每个逻辑计算机能运行不同操作系统而互不干扰,能较大提高资源利用率。通过虚拟化平台的搭建,可以通过客户端对不同服务器统一的管理,实现动态资源调度、安全部署和实时动态监控等功能。
ESXI 专为运行虚拟机、最大限度降低配置要求和简化部署而设计,其本身类似于一个操作系统,可安装至虚拟机,安装步骤可以参照文档 👈
里面还涉及到 Vmware vSphere Client 和 vCenter 的概念,而 VMware vSphere Hypervisor 也就是指的 EXSI,只是不同的叫法而已。
FTP 服务器
FTP(File Transfer Protocol Server) 服务器是依照 FTP 协议提供服务,在互联网上提供文件存储和访问服务的计算机。参考这里可以了解到如何在 Linux 和 window server 2008 R2 系统下进行 FTP 服务器的搭建 👈
文件服务器
在局域网中,以文件数据共享为目标,需要将供多台计算机共享的文件存放于一台计算机中。这台计算机就被称为文件服务器。参考这里可以了解到如何在 Linux 和 window server 2008 R2 系统下进行文件服务器的搭建 👈
数据仓库及 ODS
数据仓库(Data Warehouse):是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
ODS(Operational Data Store):是一个面向主题的、集成的、可变的、当前的细节数据集合,用于支持企业对于即时性的、操作性的、集成的全体信息的需求。
ODS 是短期的实时的数据,供产品或者运营人员日常使用,而数据仓库是供战略决策使用的数据;前者是可以更新的数据,数据仓库是基本不更新的反应历史变化的数据
两者并存的其中一种方案:
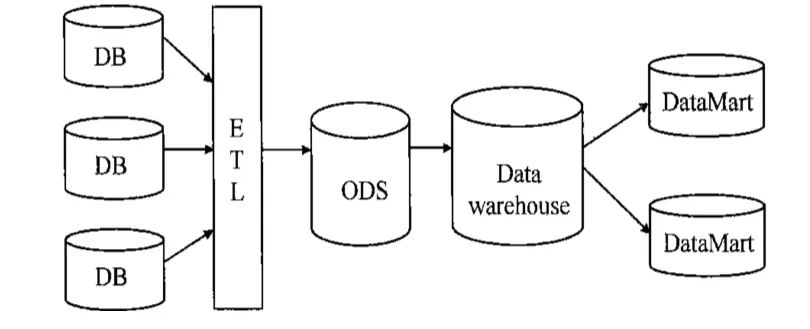
ETL 分别是Extract、Transform、Load三个单词的首字母缩写,即”抽取”、”转换”、”装载”,由于不同原始数据库中的数据的来源、格式不一样,导致了系统实施、数据整合出现问题,ETL 就是用来解决这一问题的。ETL 包含了三方面:
- 抽取 - 将数据从各种原始的业务系统中读取出来,这是所有工作的前提
- 转换 - 按照预先设计好的规则将抽取得数据进行转换,使本来异构的数据格式能统一起来
- 装载 - 将转换完的数据按计划增量或全部导入到数据仓库中
Apollo
当前我们 Node.js 项目相关的配置要么是硬编码在项目代码里,要么是通过环境变量来进行控制。对于变动不频繁的配置数据,这两种方法非常适合,但是对于一些需要经常变动,或者变动时效性要求较高的配置,每次都要经过修改代码再发布版本,才能使变动生效这样的流程就显得比较繁琐了(环境变量的修改也需要重启 pm2 进程)。
Apollo 是一款可靠的分布式配置管理中心,诞生于携程框架研发部,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。在 Apollo 后台新建或者更新了配置,我们的代码会立即生效吗?不会,更新数据采取的是应用主动拉取(轮询)机制,所以在 Apollo 更改了配置,应用并不能立即更新。对于我们的 Node.js 应用来讲,为了分散获取 Apollo 服务的压力,有意错开了每个进程的拉取时间间隔。当前我们实际设置是,从在 Apollo 后台更新完数据开始算起,每个进程都获取到最新配置数据的时间应该不会超过 3 分钟。
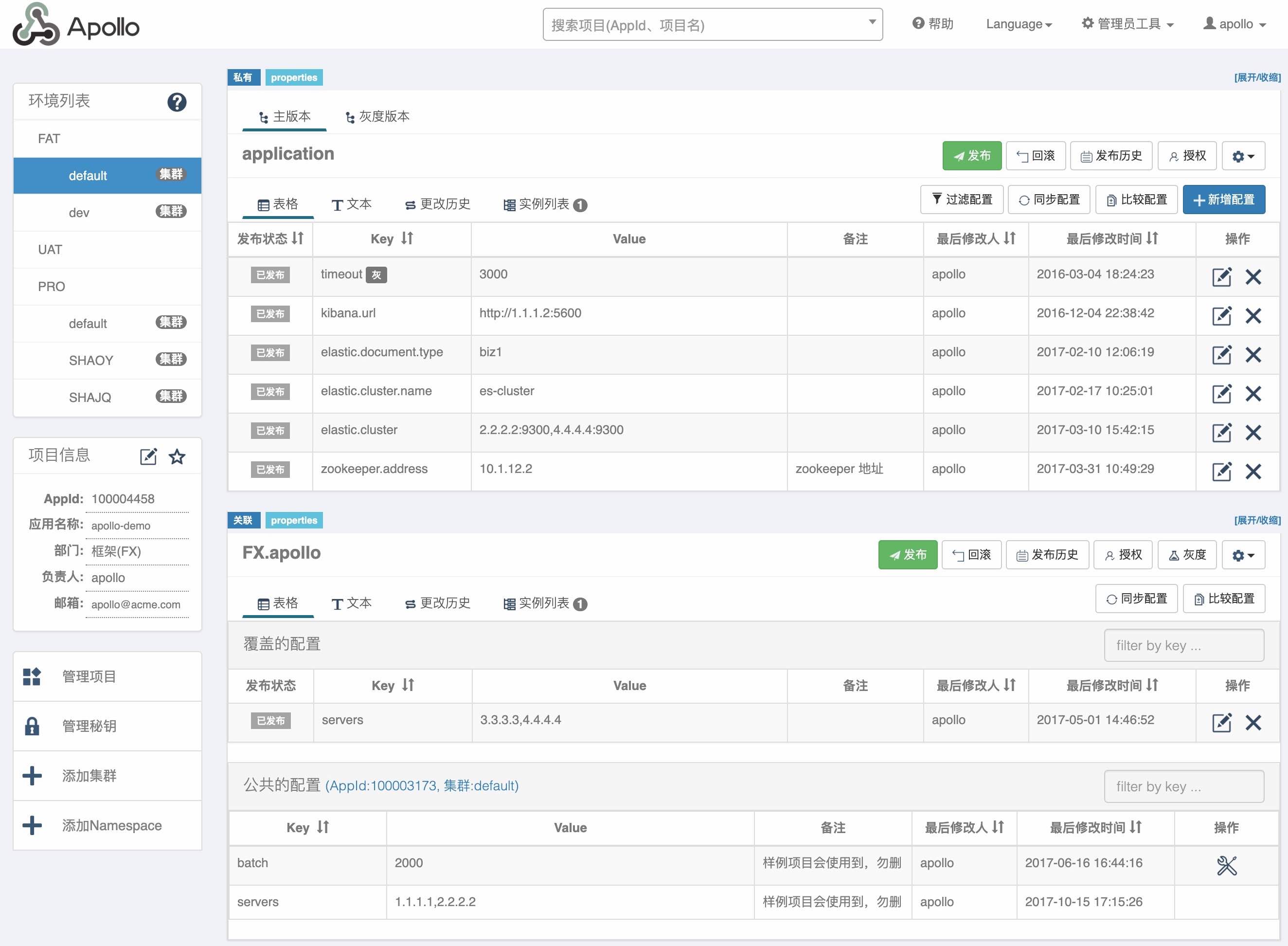
如下即是 Apollo 的基础模型:
- 用户在配置中心对配置进行修改并发布
- 配置中心通知 Apollo 客户端有配置更新
- Apollo 客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
- 同时会保存在内存中,在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置
- 应用程序可以从 Apollo 客户端获取最新的配置、订阅配置更新通知
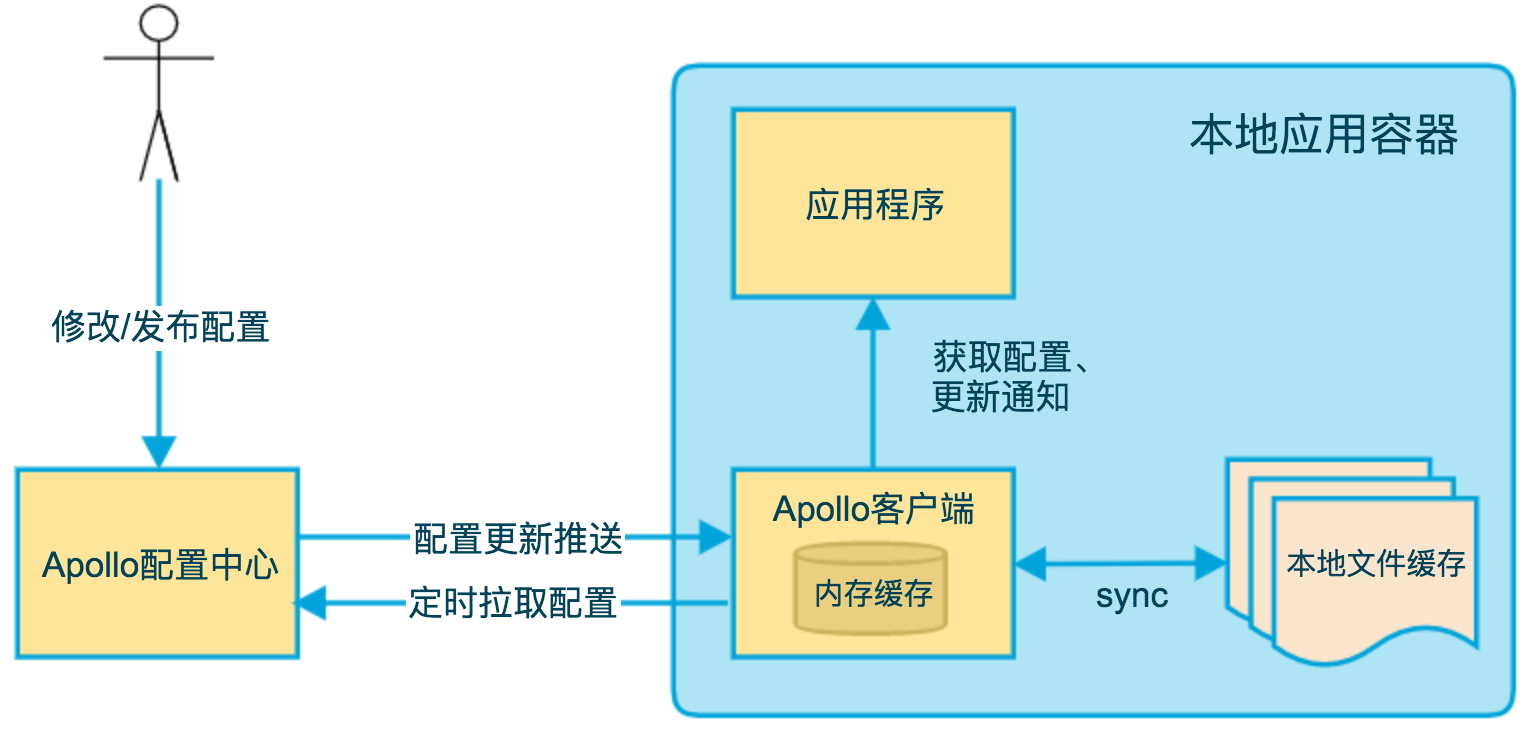
里面涉及到的 namespace 是配置项的集合,类似于一个配置文件的概念。Apollo 在创建项目的时候,都会默认创建一个名为 “application” 的 Namespace。顾名思义,“application” 是给应用自身使用的,熟悉 Spring Boot 的同学都知道,Spring Boot 项目都有一个默认配置文件 application.yml。在这里 application.yml 就等同于 “application” 的 Namespace。对于 90% 的应用来说,“application” 的 Namespace 已经满足日常配置使用场景了。上面图示中的 FX.apollo 就是 namespace。
以 node 为例,我们使用第三方仓库 ctrip-apollo:
const apollo = require('ctrip-apollo')
const ns = apollo({
host: 'http://localhost:8070',
appId: '100004458',
enableUpdateNotification: false, // set to false to disable update notification
enableFetch: true,
cachePath: path.join(__dirname, '../config'), // path specify this option to enable the feature to save configurations to the disk
fetchInterval: createInterval(), // interval in milliseconds to pull the new configurations. Defaults to 5 minutes. Setting this option to 0 will disable the feature.
fetchTimeout: 5000,
})
const start = async () => {
// We can also use async/await
await ns.ready()
console.log(ns.config())
// {
// 'portal.elastic.document.type': 'biz',
// 'portal.elastic.cluster.name': 'hermes-es-fws'
// }
}
start()
Kafka
Kafka 是最初由 Linkedin 公司开发,是一个分布式、分区的、多副本的、多订阅者,基于 zookeeper 协调的分布式日志系统(也可以当做 MQ 系统),常见可以用于 web/nginx 日志、访问日志,消息服务等等,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。采用的是发布订阅模式。
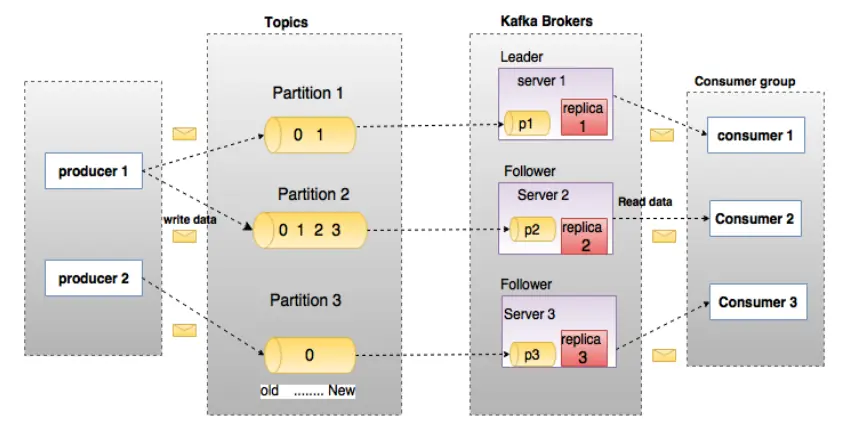
- broker - Kafka 集群包含一个或多个服务器,服务器节点即称为 broker
- topic - 主题,由用户定义并配置在 Kafka 服务器,用于建立 Producer 和 Consumer 之间的订阅关系。生产者发送消息到指定的 Topic 下,消息者从这个 Topic 下消费消息
- partition - 消息分区,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id,即 offset
- producer - 生产者即数据的发布者,该角色将消息发布到 Kafka 的 topic 中
- consumer - 消费者可以从 broker 中读取数据。消费者可以消费多个 topic 中的数据
- cosumer group - 消费者分组,用于归组同类消费者。每个 consumer 属于一个特定的 consumer group,多个消费者可以共同消费一个 Topic 下的消息
- offset - 消息在 partition 中的偏移量。每一条消息在 partition 都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息
OpenTracing & jaeger
本节主要摘自 开放分布式追踪(OpenTracing)入门与 Jaeger 实现。
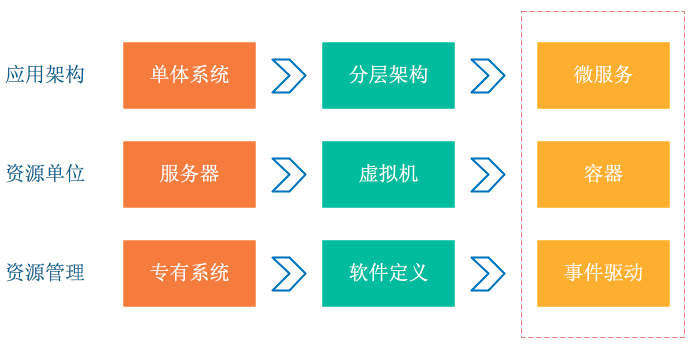
从上图我们可以看到,应用架构开始从单体系统逐步转变为微服务,其中的业务逻辑随之而来就会变成微服务之间的调用与请求。资源角度来看,传统服务器这个物理单位也逐渐淡化,变成了看不见摸不到的虚拟资源模式。从以上两个变化可以看到这种弹性、标准化的架构背后,原先运维与诊断的需求也变得越来越复杂。为了应对这种变化趋势,诞生一系列面向 DevOps 的诊断与分析系统,包括集中式日志系统(Logging),集中式度量系统(Metrics)和分布式追踪系统(Tracing):
- Logging - 用于记录离散的事件。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。
- Metrics - 用于记录可聚合的数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加。
- Tracing - 用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。
通过上述信息,我们可以对已有系统进行分类。例如,Zipkin 专注于 tracing 领域;Prometheus 开始专注于 metrics;ELK,阿里云日志服务这样的系统开始专注于 logging 领域。
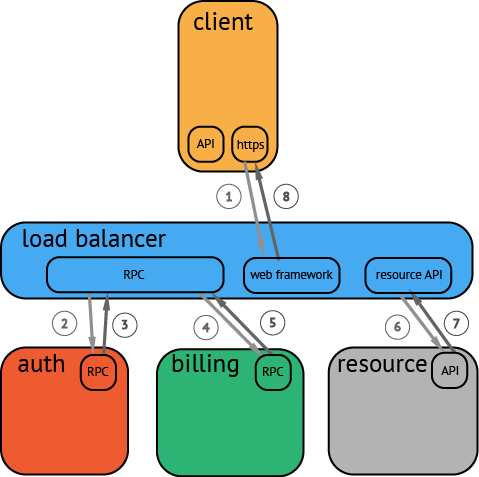
分布式追踪系统发展很快,种类繁多,比如 Google 的 Dapper,Twitter 的 Zipkin 等,但核心步骤一般有三个:代码埋点,数据存储、查询展示。下图是一个分布式调用的例子,客户端发起请求,请求首先到达负载均衡器,接着经过认证服务,计费服务,然后请求资源,最后返回结果:
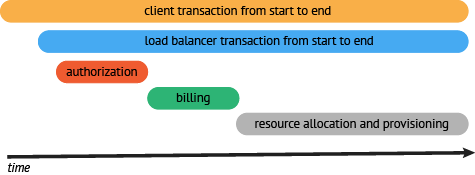
数据被采集存储后,分布式追踪系统一般会选择使用包含时间轴的时序图来呈现这个 Trace。但在数据采集过程中,由于需要侵入用户代码,并且不同系统的 API 并不兼容,这就导致了如果您希望切换追踪系统,往往会带来较大改动:
于是为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
+-------------+ +---------+ +----------+ +------------+
| Application | | Library | | OSS | | RPC/IPC |
| Code | | Code | | Services | | Frameworks |
+-------------+ +---------+ +----------+ +------------+
| | | |
| | | |
v v v v
+------------------------------------------------------+
| OpenTracing |
+------------------------------------------------------+
| | | |
| | | |
v v v v
+-----------+ +-------------+ +-------------+ +-----------+
| Tracing | | Logging | | Metrics | | Tracing |
| System A | | Framework B | | Framework C | | System D |
+-----------+ +-------------+ +-------------+ +-----------+
大多数分布式追踪系统的思想模型都来自Google’s Dapper论文,OpenTracing也使用相似的术语:
- Trace - 事物在分布式系统中移动时的描述
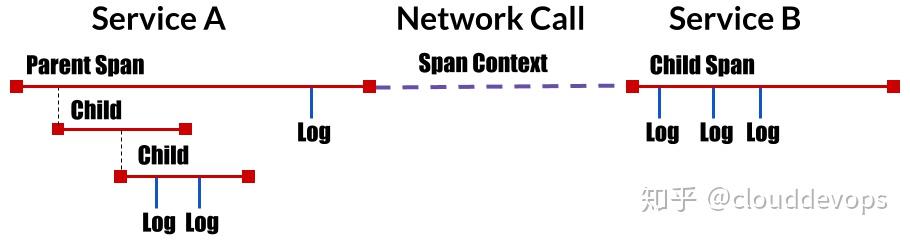
- Span - 一种命名的、定时的操作,表示工作流的一部分。Spans 接受 key:value 标签以及附加到特定 Span 实例的细粒度、带时间戳的结构化日志
- Span Context - 携带分布式事务的跟踪信息,包括当它通过网络或消息总线将服务传递给服务时。SPAN 上下文包含 Trace 标识符、SPAN 标识符和跟踪系统需要传播到下游服务的任何其他数据
Jaeger 受 Dapper 和 OpenZipkin 的启发, 是由 Uber Technologies 作为开源发布的分布式跟踪系统,兼容 OpenTracing API。它用于监视和诊断基于微服务的分布式系统,包括分布式上下文传播、分布式交易监控、根本原因分析、服务依赖性分析和性能/延迟优化等。
具体历程可以参考 uber 发布的文章 👈
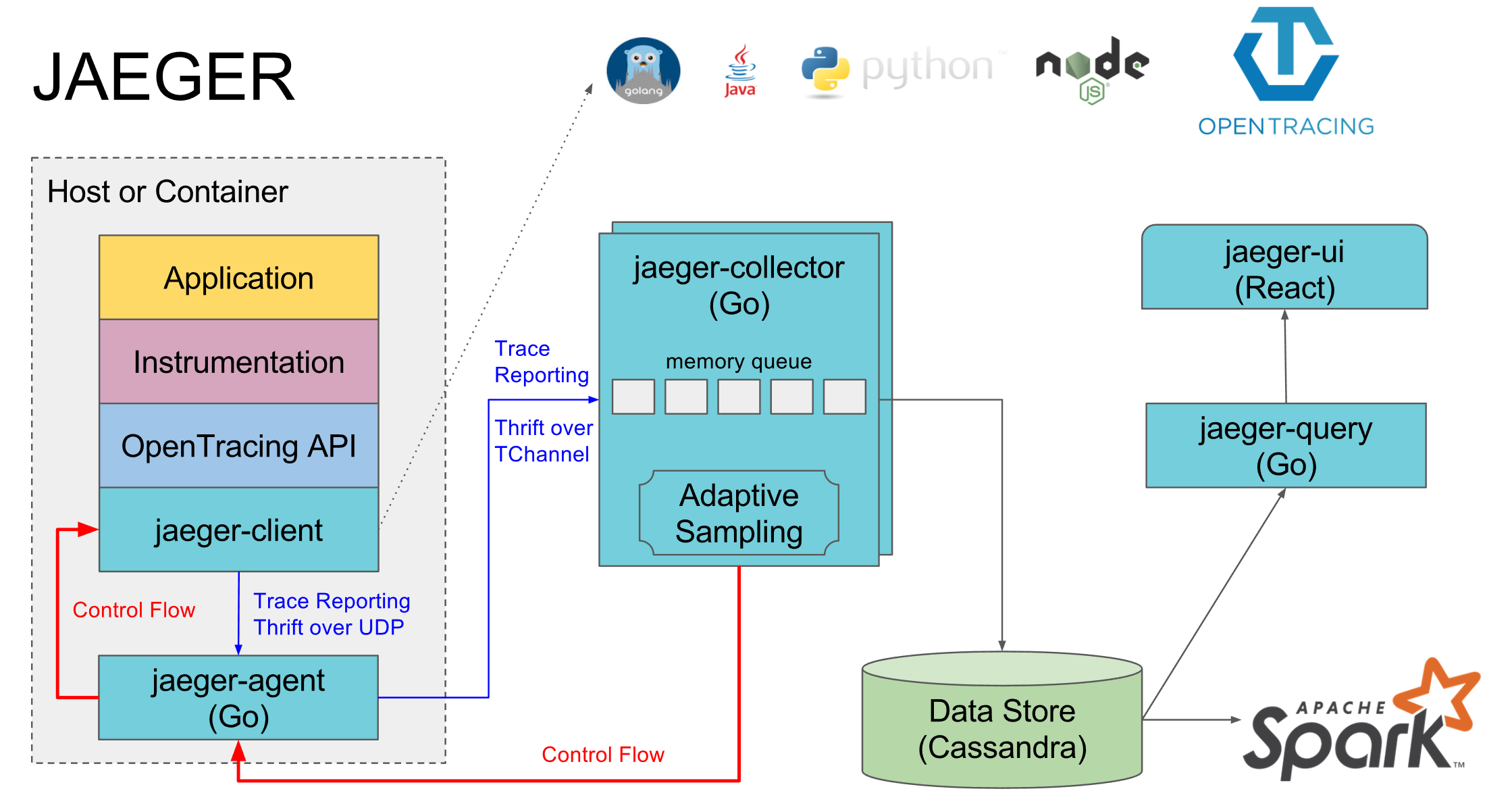
如上图所示,Jaeger 主要由以下几部分组成:
- Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
- Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
- Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
- Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elasticsearch。
- Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
Elasticsearch
全文检索
Elasticsearch 是一个实时的分布式搜索分析引擎,底层是开源库 Apache Lucene。它屏蔽了 Lucene 各种复杂的设置,为开发人员提供了很友好的便利,很多传统的关系型数据库也提供全文检索,有的是基于 Lucene 内嵌,有的是基于自研,与 Elasticsearch 比较起来,功能单一,性能也表现不是很好,扩展性几乎没有。ES 能让你以前所未有的速度和规模,去探索你的数据。它被用作全文检索、结构化搜索、分析以及这三个功能的组合。GitHub 也是使用 Elasticsearch 对海量代码进行查询。
另一个比较流行的搜索引擎也是基于 Lucene 开发的 Apache Solr,读作 “solar”。
Elasticsearch 采用的是倒排索引算法 👈
Elasticsearch 本质是一个数据库,也需要有专门的 DBA 运维,只是更偏重应用层面,所以运维职责相对传统 DBA 没有那么严苛。对于集群层面必须掌握集群搭建,集群扩容、集群升级、集群安全、集群监控告警等;另外对于数据层面运维,必须掌握数据备份与还原、数据的生命周期管理,还有一些日常问题诊断等。
详细教程可以查看这里 👈
ELK 之 Kibana
著名的 ELK 三件套,讲的就是 Elasticsearch,Logstash,Kibana,专门针对日志采集、存储、查询设计的产品组合。当然现在已经发展成了 Elastic Stack。
Logstash 是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”(当然可以就是 Elasticsearch)。
Kibana 是一种数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。它提供了强大且易用的功能,例如直方图、线形图、饼图、热图和内置的地理空间支持。此外,它还提供了与 Elasticsearch 的紧密集成,这使得 Kibana 成为了可视化 Elasticsearch 中存储数据的默认之选。
Grafana
Grafana 是一款用 Go 语言开发的开源数据可视化工具,可以做数据监控和数据统计,并带有告警功能:
The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
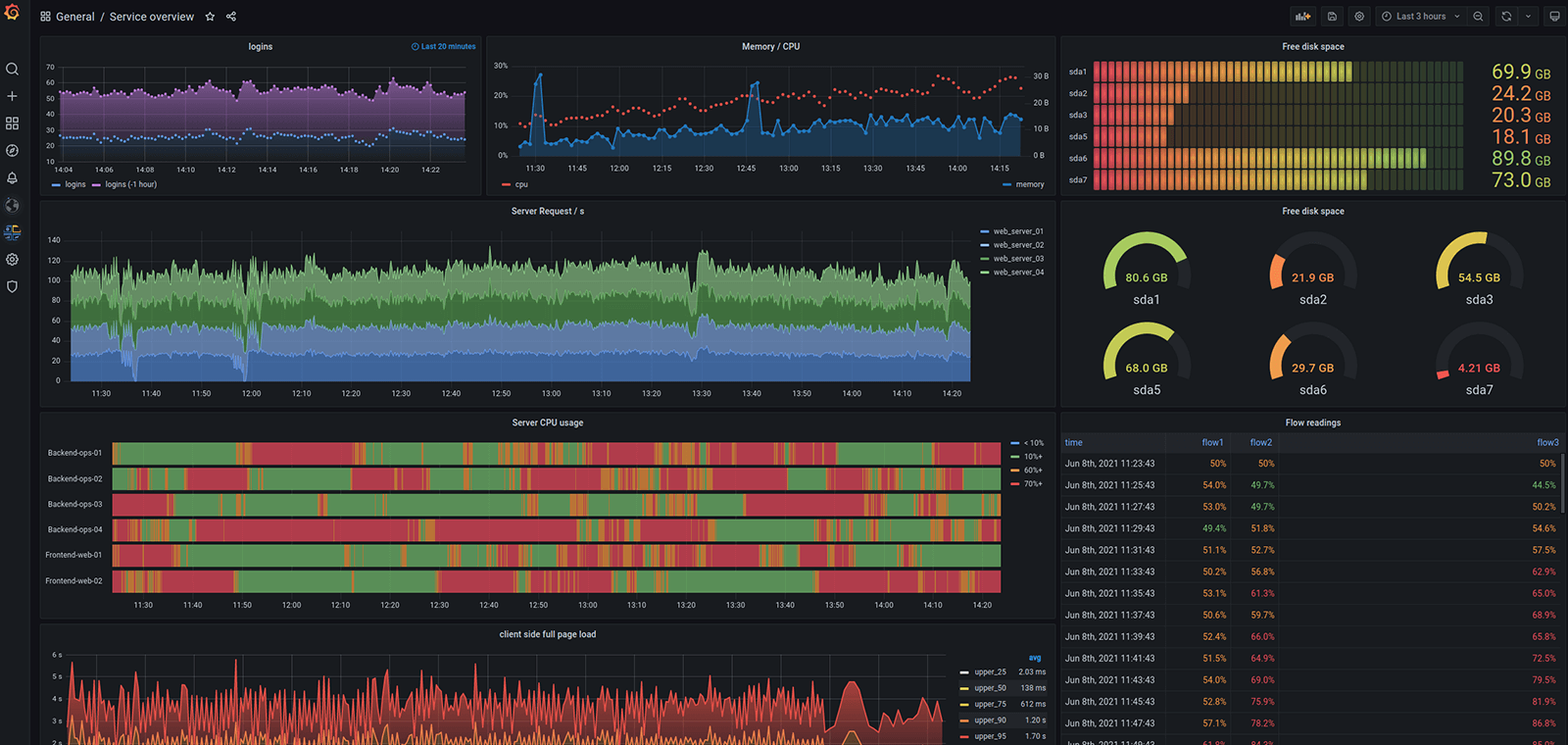
Kibana 和 Grafana 都是强大的可视化工具。然而,Grafana 和 InfluxDB 组合是用于度量数据的,反之,Kibana 是流行的 ELK 栈的一部分,它可以更为灵活地浏览日志数据。这两个平台都是好的选择,甚至有时还可以互补。首先,用 Kibana 去分析你的日志。然后,把数据导入到 Grafana 作为可视化层。
Zabbix
Zabbix 是一个基于 web 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案,基于 Server-Client 架构。主要由两部分组成:
- zabbix server - 通过 SNMP、zabbix agent、ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能
- zabbix agent - 安装在被监视的目标服务器上,它主要完成对硬件信息或与操作系统有关的内存、CPU 等信息的收集
另外 grafana 平台也可以接入 zabbix 数据进行展示,替换掉 zabbix 自带的出图界面:
- 在任意一台电脑上安装 zabbix-server,然后再在被测试的性能服务器上安装 zabbix-agent,这样,就可以把性能测试过程中,性能服务器各种监控数据给 zabbix-server
- 在任意一台电脑上安装 grafana,然后再安装 zabbix 插件,这样,就可以让 grafana 支持 zabbix
- 在 grafana 中,配置 zabbix-server 作为数据源,再添加展示面板,这样,就能把用 zabbix 监控的被测试的性能服务器的数据在 grafana 中展示了
更多文章可以参考:
- 具体安装方法可以参考这篇文章
- zabbix 从听说到学会 By JokerW
- Zabbix 3.0 从入门到精通(zabbix 使用详解) By 惨绿少年
Prometheus
Prometheus 是由前 Google 工程师从 2012 年开始在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。详情可以参考中文文档 👈
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化:
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
Prometheus 与 zabbix 的对比可以参考这篇文章。总结一下就是:如果监控的是物理机,用 Zabbix 没毛病,Zabbix 在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势。甚至环境变动不会很频繁的情况下,Zabbix 也会比 Prometheus 好使;但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是 Prometheus 吧,毕竟人家就是干这个的。Prometheus 开始成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。如果是刚刚要上监控系统的话,不用犹豫了,Prometheus 准没错。

SonarQube
SonarQube 是管理代码质量一个开放平台,可以快速的定位代码中潜在的或者明显的错误。可通过安装不同的插件,sonar 可以集成测试工具、代码质量分析工具、持续集成等多种功能。SonarQube 架构主要由:SonarQube 服务器、sonar 数据库、插件、SonarQube scanners 四部分组成。

Sonar 实际上是一个 Web 系统,展现了静态代码扫描的结果,真正实现代码扫描的是 SonarQube Scanner 这个工具,可以支持多种开发语言。SonarQube 需要数据库的支持,用于存储检测项目后的分析数据,同时为了实现可持续监测,还需要持续集成工具(如 Jenkins)的支持,在构建版本前,通过 Jenkins + Sonar 插件执行项目分析指令,最终的结果会通过 SonarQube 服务器的 Web 页面展示。下图是使用 SonarQube 做代码持续审查的简易流程图:

- Developers develop and merge code in an IDE (preferably using SonarLint to receive immediate feedback in the editor) and check-in their code to their DevOps Platform.
- An organization’s continuous integration (CI) tool checks out, builds, and runs unit tests, and an integrated SonarQube scanner analyzes the results.
- The scanner posts the results to the SonarQube server which provides feedback to developers through the SonarQube interface, email, in-IDE notifications (through SonarLint), and decoration on pull or merge requests (when using Developer Edition and above).
ZooKeeper
ZooKeeper 是开源的分布式应用程序协调服务。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。已经作为核心组件被广泛应用在很多大型分布式系统中,包括 Hadoop、Hbase、Storm、Kafka、Dubbo 等。
Zookeeper 是一个由多个 server 组成的集群,一个 leader,多个 follower(这个不同于我们常见的 Master/Slave 模式)。leader 为客户端服务器提供读写服务,除了 leader 外其他的机器只能提供读服务。每个 server 保存一份数据副本全数据一致,分布式读 follower,写由 leader 实施更新请求转发,由 leader 实施更新请求顺序进行,来自同一个 client 的更新请求按其发送顺序依次执行数据更新原子性,一次数据更新要么成功,要么失败。全局唯一数据视图,client 无论连接到哪个 server,数据视图都是一致的实时性,在一定事件范围内,client 能读到最新数据。
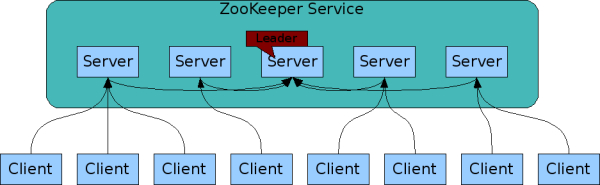
由于 ZooKeeper 集群选举 leader 需要遵循过半机制:“存活的节点数 > 总节点数 / 2”。一般采用奇数个的节点主要是出于两方面的考虑:
1、防止由脑裂造成的集群不可用。
首先,什么是脑裂?集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的 master 节点,导致原有的集群出现多个 master 节点的情况,这就是脑裂。
假如 ZooKeeper 集群有 5 个节点,脑裂成了 A、B 两个小集群,要么 (2、3),要么 (1、4),满足上述的过半机制;如果集群有 4 个节点,则要么 (2、2),要么 (1、3)。显然 (2、2) 是没办法提供服务的。因此针对脑裂成 2 个集群的情况下,推荐使用奇数台服务器。
2、容灾能力的角度。
根据过半机制验证:
1)假设集群有 3 台服务器,1 台 Leader,2 台 Follower。
Leader 挂掉,那么剩下 2 台服务器,即 2>(3/2=1) 条件成立,那么可以选举出 1 个 Leader
2)假设集群有 4 台服务器,1 台 Leader,3 台 Follower。
Leader 挂掉,那么剩下 3 台服务器,即 3>(4/2=2) 条件成立,那么可以选举出 1 个 Leader
3)假设集群有 4 台服务器,1 台Leader,3 台 Follower。
Leader 和一台 Follower 挂掉,那么剩下 2 台服务器,即 2>(4/2=2) 条件不成立,那么不可以选举出 Leader
依次类推.......
结论: 2n-1 台和 2n 台服务器容灾能力一样,大可不必多花一台服务器部署
xxl-job
定时任务调度与执行
项目开发中,常常以下场景需要分布式任务调度:
- 同一服务多个实例的任务存在互斥时,需要统一协调
- 定时任务的执行需要支持高可用、监控运维、故障告警
- 需要统一管理和追踪各个服务节点定时任务的运行情况,以及任务属性信息,例如任务所属服务、所属责任人
因此,XXL-JOB 应运而生: XXL-JOB 是一个开源的轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展、开箱即用,其中 XXL 是主要作者大众点评许雪里名字的缩写。主要功能特性如下:
- 简单灵活
- 提供 Web 页面对任务进行管理,管理系统支持用户管理、权限控制;
- 支持容器部署;
- 支持通过通用 HTTP 提供跨平台任务调度;
- 丰富的任务管理功能
- 支持页面对任务 CRUD 操作;
- 支持在页面编写脚本任务、命令行任务、Java 代码任务并执行;
- 支持任务级联编排,父任务执行结束后触发子任务执行;
- 支持设置任务优先级;
- 支持设置指定任务执行节点路由策略,包括轮询、随机、广播、故障转移、忙碌转移等;
- 支持 Cron 方式、任务依赖、调度中心 API 接口方式触发任务执行
- 高性能
- 调度中心基于线程池多线程触发调度任务,快任务、慢任务基于线程池隔离调度,提供系统性能和稳定性;
- 任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰;
- 高可用
- 任务调度中心、任务执行节点均 集群部署,支持动态扩展、故障转移;
- 支持任务配置路由故障转移策略,执行器节点不可用是自动转移到其他节点执行;
- 支持任务超时控制、失败重试配置;
- 支持任务处理阻塞策略:调度当任务执行节点忙碌时来不及执行任务的处理策略,包括:串行、抛弃、覆盖策略;
- 易于监控运维
- 支持设置任务失败邮件告警,预留接口支持短信、钉钉告警;
- 支持实时查看任务执行运行数据统计图表、任务进度监控数据、任务完整执行日志;
系统组成:
- 调度模块(调度中心):
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
- 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE 开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器 Failover。
- 执行模块(执行器):
- 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
- 接收 “调度中心” 的执行请求、终止请求和日志请求等。
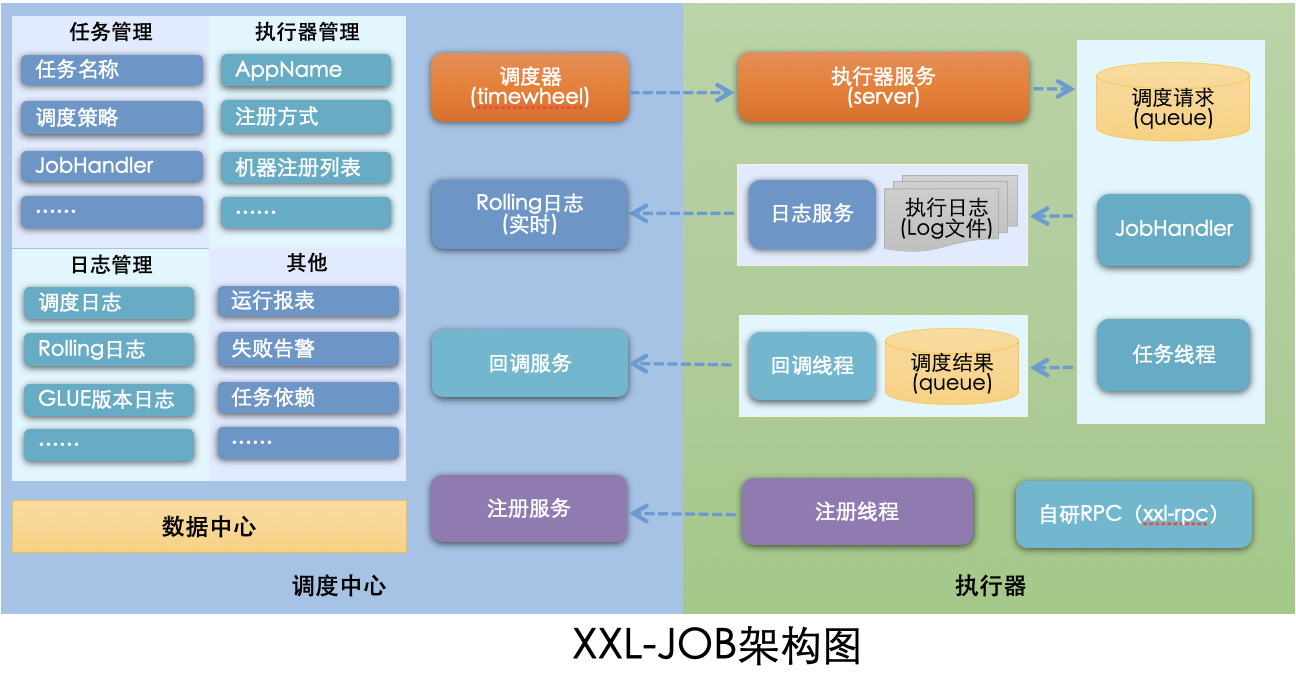
工作原理:
- 任务执行器根据配置的调度中心的地址,自动注册到调度中心
- 达到任务触发条件,调度中心下发任务
- 执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
- 执行器的回调线程消费内存队列中的执行结果,主动上报给调度中心
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
cron 表达式
定时任务的执行策略通常是通过 cron 表达式来完成。cron 表达式是一个字符串,该字符串由 6 个空格分为 7 个域,每一个域代表一个时间含义。 格式如下。 cron 表达式的难点即在于通配符的使用:
[秒] [分] [时] [日] [月] [周] [年]
| 域 | 是否必填 | 值以及范围 | 通配符 |
| 秒 | 是 | 0-59 | , - * / |
| 分 | 是 | 0-59 | , - * / |
| 时 | 是 | 0-23 | , - * / |
| 日 | 是 | 1-31 | , - * ? / L W |
| 月 | 是 | 1-12 或 JAN-DEC | , - * / |
| 周 | 是 | 1-7 或 SUN-SAT | , - * ? / L # |
| 年 | 否 | 1970-2099 | , - * / |
- , - 这里指的是在两个以上的时间点中都执行,如果我们在 “分” 这个域中定义为 8,12,35 ,则表示分别在第 8 分,第 12 分 第 35 分执行该定时任务。
- - - 这个比较好理解就是指定在某个域的连续范围,如果我们在 “时” 这个域中定义 1-6,则表示在 1 到 6 点之间每小时都触发一次,用,表示 1,2,3,4,5,6
- * - 表示所有值,可解读为 “每”。 如果在 “日” 这个域中设置 *, 表示每一天都会触发。
- ? - 表示不指定值。使用的场景为不需要关心当前设置这个字段的值。例如:要在每月的 8 号触发一个操作,但不关心是周几,我们可以这么设置 0 0 0 8 * ?
- /- 在某个域上周期性触发,该符号将其所在域中的表达式分为两个部分,其中第一部分是起始值,除了秒以外都会降低一个单位,比如 在 “秒” 上定义 5/10 表示从 第 5 秒开始 每 10 秒执行一次,而在 “分” 上则表示从 第 5 秒开始 每 10 分钟执行一次。
- L - 表示英文中的 LAST 的意思,只能在 “日” 和 “周” 中使用。在 “日” 中设置,表示当月的最后一天 (依据当前月份,如果是二月还会依据是否是润年), 在 “周” 上表示周六,相当于”7” 或”SAT”。如果在”L” 前加上数字,则表示该数据的最后一个。例如在 “周” 上设置”7L” 这样的格式,则表示 “本月最后一个周六”
- W - 表示离指定日期的最近那个工作日 (周一至周五) 触发,只能在 “日” 中使用且只能用在具体的数字之后。若在 “日” 上置”15W”,表示离每月 15 号最近的那个工作日触发。假如 15 号正好是周六,则找最近的周五 (14 号) 触发,如果 15 号是周未,则找最近的下周一 (16 号) 触发。如果 15 号正好在工作日 (周一至周五),则就在该天触发。如果是 “1W” 就只能往本月的下一个最近的工作日推不能跨月往上一个月推。
- # - 表示每月的第几个周几,只能作用于 “周” 上。例如 ”2#3” 表示在每月的第三个周二。
举几个示例,以上摘自文章 - 详解定时任务中的 cron 表达式 👈:
每隔 1 分钟执行一次:0 */1 * * * ?
每天 22 点执行一次:0 0 22 * * ?
每月 1 号凌晨 1 点执行一次:0 0 1 1 * ?
每月最后一天 23 点执行一次:0 0 23 L * ?
每周周六凌晨 3 点实行一次:0 0 3 ? * L
在 24 分、30 分执行一次:0 24,30 * * * ?
AWS S3 / OSS
随着业务的发展,需要管理急剧增加并且孤立的大量数据,这些数据来自很多被任意数量的应用程序和业务流程使用的来源。现在,很多公司都面临着碎片化存储产品带来的挑战。这些产品不仅增加了业务应用程序的复杂性,还减缓了其创新速度。对象存储能够提供可以大规模扩展并且经济高效的存储来以原生格式存储任何类型的数据,从而打破这些限制。
AWS(Amazon Web Services) 是 Amazon 公司旗下云计算服务平台,为全世界范围内的客户提供云解决方案。面向用户提供包括弹性计算、存储、数据库、应用程序在内的一整套云计算服务,帮助企业降低 IT 投入成本和维护成本。同类型的还可以了解下 Azure、阿里云、腾讯云、首都在线等。
Amazon Simple Storage Service(Amazon S3) 提供高持久性、高扩展性且安全的目标,用于备份和存档关键数据。S3 可以存储任意大小的内容,并且允许用户从任意位置访问。是唯一一个允许您直接在静态数据上运行复杂大数据分析的云存储平台,无需您提取数据以及将其加载到单独的分析系统。您可以使用 Amazon Athena 或 Amazon Redshift Spectrum 查询 S3 数据,而不占用任何其他基础设施,并仅需为您运行的查询付费。这样便可对使用 SQL 的所有人都能访问的大量非结构化数据进行分析,与传统提取、转换和加载 (ETL) 过程相比更为经济高效。
S3 的数据都是存储在 AWS 的存储桶中,我们可以把桶理解为磁盘分区,不过它是由一个桶名(字符串)唯一标识,即你不能创建别人已经创建过的桶。S3 能够实现卓越的数据保护,跨区域复制 (CRR) 将把每个 S3 对象自动复制到位于不同 AWS 区域的一个目标存储桶。除此之外还可以定义生命周期规则,从而将非频繁访问数据自动迁移到 S3 Standard – Infrequent Access,并将对象集合存档到 Amazon Glacier 中。
Amazon Glacier 也是 Amazon 提供的存储解决方案,适用于数据存档和长期备份。它们能够提供 99.999999999% 的持久性以及全面的安全与合规功能,可以帮助满足最严格的监管要求。客户能以每月每 TB 低至 1 USD 的价格存储数据,与本地解决方案相比,显著降低了成本。为了保持低廉成本,同时满足各种检索需求,Amazon S3 Glacier 提供了三种访问存档的选项,检索时间从数分钟到数小时不等;S3 Glacier Deep Archive 提供了两种访问选项,检索时间从 12 小时到 48 小时不等。
阿里云对象存储服务(Object Storage Service,即 OSS)是阿里云提供的海量、安全、低成本、高可靠的云存储服务。可以使用阿里云提供的 API、SDK 接口或者 OSS 迁移工具轻松地将海量数据移入或移出阿里云 OSS。数据存储到阿里云 OSS 以后,您可以选择标准存储(Standard)作为移动应用、大型网站、图片分享或热点音视频的主要存储方式,也可以选择成本更低、存储期限更长的低频访问存储(Infrequent Access)和归档存储(Archive)作为不经常访问数据的存储方式。
推送服务
无论是哪种类型的通知,只有进行精细化地推送,即在合适的时候给合适的人群推送合适的内容,才能在不打扰用户、给用户带来价值的同时,有效延伸产品价值。😊
关于推送服务的前世今生,可以参考少数派这篇文章 👈
Firebase Cloud Messaging
Firebase 是一个来自 Google 的基于云托管的移动应用程序开发平台,具有强大的开发、处理和增强应用程序的功能。本质上是一个开发人员可以依赖的工具集合,可以根据需求创建应用程序并对其进行扩展。Google Firebase 平台的一些突出特性包括数据库、身份验证、推送消息、分析、文件存储等等。旨在为开发者解决三大问题:
- 快速开发应用
- 充满信心地发布和监控应用程序
- 吸引用户

Firebase 的优势:
- 免费开始 - Firebase 的 Spark 套餐是免费的,提供了许多功能来帮助开发者入门。基于不断增长的需求,后期可以换到 Blaze 套餐。
- 开发速度 - 提供了多种随时可用的服务,这些服务可以避免开发人员使用样板代码、重造轮子以及从头开始创建后端。包括通知、单点登录和分析。
- 无需服务器 - Firebase 提供了一个无服务器架构,用户只有在需要使用服务器的情况下才需要支付费用。不需要管理或担心服务器基础设施。
- 机器学习 - 提供了一个机器学习工具包,该工具包包含针对不同移动平台的 api,如文本识别、人脸检测、图像标签、条形码扫描等。
- 带来流量 - Firebase 通过在 Search 上提供应用程序链接,促进应用程序索引,让用户重新与 Google 搜索用户建立联系。应用程序的排名也可以通过索引一个应用程序来提高一次,这有助于你的应用程序获得可以安装它的新用户的曝光率。
- 错误监控 - Firebase 的 Crashlytics 特性是一个非常棒的工具,可以快速查找和修复问题。Firebase 可以监控非致命性和致命性错误,并根据错误如何影响用户体验生成报告。
- 备份 - Firebase 通过定期备份确保数据的最佳安全性和可用性,Blaze 套餐的用户可以轻松地配置 firebaserealtimedatabase 以进行自动备份
- Cloud Messaging 云消息传递 - FCM 可以跨各种平台(Android、iOS 和网页)免费向用户发送消息和通知。消息可以发送到单个设备、设备组、订阅了特定主题的用户或细分用户群。FCM 可以根据应用进行扩展,即使是规模最大的应用也能处理,每天可传送数千亿条消息。
- A/B 测试 - 通过运行产品和营销实验来改进您的应用,而无需费心设置运行 A/B 测试的基础架构。自定义实验以满足您的目标。测试应用的各种更新,例如消息副本或新功能。然后,只发布证明可以对改善关键指标起到作用的更改。
Firebase 的局限性:
- 它不是开源的 - 具有很大的限制,虽然这个平台不是开源的,但是需要强调的是很多库和 sdk 都可以在 GitHub 上使用
- 部分国家都不能正常使用 - 部分国家谷歌服务屏蔽,具体查看 Transparency Report
- 只有 NoSQL 数据库可用 - Firebase 的数据库类别 Firestore 数据库和 Firebase Realtime 数据库都提供了 NoSQL 结构,而且没有使用关系数据库的选项。
- 查询缓慢
- 并非所有服务都可以免费开始使用 - 比如上面提到的机器学习
- 它并不便宜,价格也难以预测 - 这就是为什么许多开发者最终选择自主托管应用程序,比如 Digital Ocean,AWS,或者 Google Cloud。
- 只能在谷歌云上运行 - Firebase 现在是 Google 的一部分,它的基础设施完全在 Google Cloud 上运行。在 AWS、 Azure 或 Digital Ocean 等其他云提供商上运行 Firebase 是没有选择的
- 不提供 GraphQL api - Firebase 不提供 GraphQL api 作为标准设置的一部分。尽管使用 Firebase 实现 GraphQL 有一些变通方法,REST 仍然是平台的默认选项。
上面介绍了 Firebase 平台的功能,其中 Firebase Cloud Messaging (FCM) 是一种跨平台消息传递解决方案,可供您可靠地传递消息,且无需任何费用。在即时通讯等使用情形中,一条消息可将最多 4000 字节的载荷传送至客户端应用。FCM 实现包括用于发送和接收的两个主要组件:
- 一个受信任的环境,例如 Cloud Functions for Firebase 或用于构建、定位和发送消息的应用服务器。
- 一个通过针对具体平台的相应传输服务接收消息的 iOS、Android 或 Web (JavaScript) 客户端应用。
- Android 传输层 (ATL),适用于运行 Google Play 服务的 Android 设备
- 适用于 iOS 设备的 Apple 推送通知服务 (APNs)
- Web 应用的网络推送协议 Web Push

如需使用 Admin SDK 或 FCM 协议以编程方式发送通知消息,可使用通知消息中用户可见部分所必需的预定义键值选项集来设置 notification 键。例如,以下是 IM 应用中的 JSON 格式的通知消息。用户可能会在设备上看到标题为 “Portugal vs. Denmark”、文本为 “great match!” 的消息。应用在后台运行时,通知消息将被传递至通知面板。应用在前台运行时,消息由回调函数处理:
{
"message":{
"token": "bk3RNwTe3H0:CI2k_HHwgIpoDKCIZvvDMExUdFQ3P1...",
"notification": {
"title": "Portugal vs. Denmark",
"body": "great match!"
}
}
}
当然也可以针对具体平台的采取不同的通知消息:
// 为 Android 和 Web 平台设置较长的存留时间,同时将 APNs (iOS) 消息设置为低优先级
// 设置相应的键来定义 Android 和 iOS 上的用户点按通知的结果,分别为 click_action 和 category
{
"message": {
"token": "bk3RNwTe3H0:CI2k_HHwgIpoDKCIZvvDMExUdFQ3P1...",
"notification": {
"title": "Match update",
"body": "Arsenal goal in added time, score is now 3-0"
},
"android": {
"ttl": "86400s",
"notification": {
"click_action": "OPEN_ACTIVITY_1"
}
},
"apns": {
"headers": {
"apns-priority": "5",
},
"payload": {
"aps": {
"category": "NEW_MESSAGE_CATEGORY"
}
}
},
"webpush": {
"headers": {
"TTL": "86400"
}
}
}
}
APNs
APNs(Apple Push Notification Service) 是 Apple 公司推出的针对 iOS 的推送服务,它通过长 IP 连接推送技术从第三方应用向苹果设备提供推送通知服务,通知中可能包括标记、声音、提醒/横幅。
- 应用程序把要发送的消息、目的 iPhone 的标识打包,发给 APNS;
- APNS 在自身的已注册 Push 服务的 iPhone 列表中,查找有相应标识的 iPhone,并把消息发送到 iPhone;
- iPhone 把发来的消息传递给相应的应用程序,并且按照设定弹出 Push 通知。
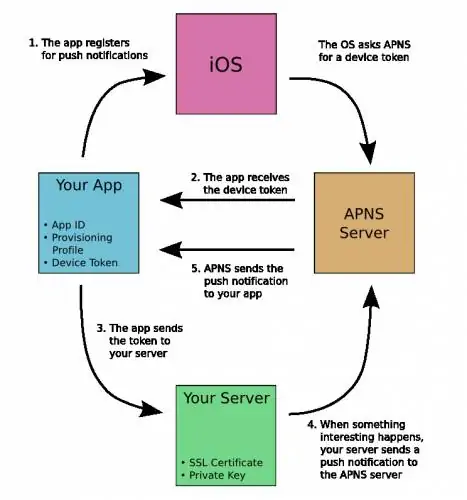
对于 iOS 设备,FCM 充当通过 APNs 发送通知的代理
华为 Push Kit
由于政治问题华为不能采用 Google FCM 那一套,所以需要采用自家推出的推送服务 Push Kit。推送服务支持通过 AppGallery Connect 控制台和 REST API 推送消息。
非华为终端设备要使用华为推送,则需要在应用市场下载安装 HMS Core(APK)。由于非华为终端设备上缺少 NC 的能力,推送功能会受到系统限制,影响消息推送的到达率。NC 是华为终端设备上预置的系统级应用,可通过华为应用市场(名称为推送服务)进行更新,主要功能是展示终端设备上应用的通知消息。
消息到达率,是衡量消息推送渠道稳定性和可靠性的关键指标。通常,应用推送消息渠道主要有两种:
- 自建推送通道 - 应用通过自建通道推送,通常需要应用的进程处于运行状态。而在大多数情况下,运营人员推送消息时,应用进程经常不在运行,除非用户主动打开应用或者授予应用某些系统级的权限。考虑到手机耗电的问题,少有用户会授予系统级别的权限给应用,这就导致了自建通道的消息到达率大大降低,从而影响推送的效果。
- 厂商推送通道 - 作为厂商推送通道,比如华为推送服务则建立了稳定的系统长连接,通过系统应用来统一展示应用消息。因此,应用获得用户的授权后,不需要常驻后台,也能把消息推送至通知栏,从而保证了应用消息的高到达率——在线到达率 99.8%。
当然除了到达率,新闻类、社交类、交易类等应用还对消息的到达速度有较高的要求。例如:在用户完成交易的那一刻,应用需要及时将交易状态通过推送反馈;好友发送的消息,应用需要在第一时间告知用户等等。但不是所有消息都具有普适性,推送的时间或内容不合适,可能会引起用户的反感。所以,推送的精细化运营也尤为重要。 将人群、场景进行划分,并针对性地推送个性化内容,是精细化运营的核心。
除了华为的 Push Kit,还有小米的 MiPush。这些推送服务被集成在各家高度定制的 Android 系统中,享有系统级地位,推送的优先级比较高。各大互联网公司也有自己的推送服务,比如腾讯信鸽推送、百度云推送、阿里云移动推送。使用这三家公司各类 Android 应用的朋友不少都知道他们的「企鹅全家桶」「百度全家桶」和「阿里全家桶」,「全家桶效应」调侃的就是 BAT 自家应用的相互唤醒,让系统变卡变慢。你打开一个淘宝,就会唤醒闲鱼、支付宝、天猫等等应用,这种相互唤醒,目的是让共用的推送通道保持活跃,而不被系统杀死,以便消息能及时送达。除了以上提到的两种推送服务,另外还有一种专业的第三方平台提供推送服务,比如极光推送、友盟推送等等。
LDAP 与 Active Directory
LDAP(Light Directory Access Portocol) 是基于 X.500 标准(网络中目录服务的标准)的轻量级目录访问协议,约定了 Client 与 Server 之间的信息交互格式、使用的端口号、认证方式等内容。目录是一个为查询、浏览和搜索而优化的数据库,它成树状结构组织数据,类似文件目录一样。目录数据库和关系数据库不同,它有优异的读性能,但写性能差,并且没有事务处理、回滚等复杂功能,不适于存储修改频繁的数据。所以目录天生是用来查询的,就好象它的名字一样。LDAP 目录服务是由目录数据库和一套访问协议组成的系统。
LDAP 的常见用途是为身份验证提供中心位置 —— 意味着它存储用户名和密码。然后,可以将 LDAP 用于不同的应用程序或服务中,以通过插件验证用户。例如,LDAP 可用于 Docker,Jenkins,Kubernetes,Open VPN 和 Linux Samba 服务器验证用户名和密码。系统管理员还可以使用 LDAP 单一登录来控制对 LDAP 数据库的访问。LDAP 还可以用于将操作添加到目录服务器数据库中,对会话进行身份验证或绑定,删除 LDAP 条目,使用不同的命令搜索和比较条目,修改现有条目,扩展条目,放弃请求或取消绑定操作。
LDAP 也可用于 Microsoft 的 Active Directory 中,但也可以用于其他工具中,例如 Open LDAP,Red Hat Directory Server 和 IBM Tivoli Directory Server。Open LDAP 是一个开源 LDAP 应用程序。它是为 LDAP 数据库控制开发的 Windows LDAP 客户端和管理工具。该工具应允许用户浏览,查找,删除,创建和更改 LDAP 服务器上显示的数据。Open LDAP 还允许用户管理密码和按架构浏览。
LDAP 是一个历史悠久的协议,诞生时间早于万维网。在当时商业数据库并不发达,而且当时商业数据库的驱动在多语言支持上也不友好——有可能这个数据库在你使用的编程语言上根本没有相关的开发包。LDAP 一直沿用至今,有很多的历史原因,因此许多应用都会支持通过 LDAP 登录。LDAP 协议的用户目录是树形结构,天然与组织机构契合,而且在查询上速度非常快,比任何其他数据库都要快。
Active Directory 是一种目录服务,用于管理域,用户和分布式资源(例如 Windows 操作系统的对象),是基于 LDAP 协议的一套解决方案,解决了细粒度的权限控制。目录服务背后的意义是它在管理域和对象的同时控制哪些用户可以访问每个资源,核心:「谁 以什么权限 访问什么」。
AD 可以管理用户的域账号、用户信息、企业通信录(与电子邮箱系统集成)、用户组管理、用户身份认证、用户授权管理、按需实施组管理策略等。在 Windows 下,有组策略管理器,如果启用域用户认证,那么这些组策略可以统一管理,方便地限制用户的权限。也可以管理服务器及客户端计算机账户、所有服务器及客户端计算机加入域管理并按需实施组策略,甚至可以控制计算机禁止修改壁纸、禁止使用 u 盘等。
计算机要通过 AD 管理的前提是加域。
端口映射和 DMZ 主机
首先解释一下“内网”与“外网”的概念:
- 内网:即所说的局域网,局域网内每台计算机的 IP 地址在本局域网内具有互异性,是不可重复的。但两个局域网内的内网 IP 可以有相同的。
- 外网:即互联网,局域网通过一台服务器或是一个路由器对外连接的网络,这个 IP 地址是唯一的。也就是说内网里所有的计算机都是连接到这一个外网 IP 上,通过这一个外网 IP 对外进行交换数据的。也就是说,一个局域网里所有电脑的内网 IP 是互不相同的,但共用一个外网 IP。(用
ipconfig/all查到的 IP 是你本机的内网 IP;在www.ip138.com上看到的是你连接互联网所使用的 IP,即外网)。
端口映射是 网络地址转换(NAT) 的一种,就是将外网主机的 IP 地址的一个端口映射到内网中一台机器,提供相应的服务。当用户访问该 IP 的这个端口时,服务器自动将请求映射到对应局域网内部的机器上。端口映射有动态和静态之分。
内网的一台电脑要上因特网或者给因特网启动服务,就需要端口映射。例如要映射一台 IP 地址为 192.168.111.10 的 WEB 服务器,只需把服务器的 IP 地址和提供 web 服务的 TCP 端口 80 填入到路由器的端口映射表中即可。
DMZ(demilitarized zone) ,即”隔离区”或”非军事化区”。它是为了解决安装防火墙后外部网络不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区,这个缓冲区位于企业内部网络和外部网络之间的小网络区域内,在这个小网络区域内可以放置一些必须公开的服务器设施,如企业 Web 服务器、FTP 服务器和论坛等。另一方面,通过这样一个 DMZ 区域,更加有效地保护了内部网络,因为这种网络部署,比起一般的防火墙方案,对攻击者来说又多了一道关卡。 DMZ 主机就是一个开放所有端口的虚拟服务器。
端口映射只是映射指定的端口,DMZ 相当于映射所有的端口,并且直接把主机暴露在网关中,比端口映射方便但是不安全。且当设置了 DMZ 主机后,所有端口的映射都将指向 DMZ 主机,指向其他电脑的端口映射将无效。
全链路压测
压测指标及工具
全链路压测是基于线上真实环境和实际业务场景,通过模拟海量的用户请求,来对整个系统进行压力测试。相对于比较简单的压测,比如只对线上的单机或集群发起服务调用;将线上流量进行录制,然后在单台机器上进行回放等。能够更全面地进行链路覆盖。以下是我们需要关注的一些指标:
| 指标 | 描述 |
|---|---|
| qps(query per second) | 每秒处理请求数 |
| tps(transactions per second) | 每秒处理的事务 |
| hps(hits per second) | 每秒点击次数 |
| rt(response time) | 响应时间,相当于 latency |
| CPU 使用率 | 出于节点宕机后负载均衡的考虑,一般 CPU 使用率小于 75% 比较合适 |
| 内存使用率 | 内存占用情况,一般观察内存是否有尖刺或泄露 |
| 缓存命中率 | 多少流量能命中缓存层(redis、memcached 等) |
tps 一个完整事务可能包含一些列的请求过程。比如访问一个网页,可以当做一个事务,但是访问一个网页可能会对多个服务器发起多次请求,这些请求会当做多次 qps 计算在内。
一般情况下用 tps 来衡量整个业务流程,用 qps 来衡量接口查询次数,用 hps 来表示对服务器单击请求。
压测工具的选择也有很多,比如 Apache ab、Apache JMeter、locust 等。也有一些轻量级的工具,如 wrk 等,我们简单看下 wrk 的输出:
# This runs a benchmark for 30 seconds, using 12 threads, and keeping 400 HTTP connections open.
$ wrk -t12 -c400 -d30s http://127.0.0.1:8080/index.html
Running 30s test @ http://127.0.0.1:8080/index.html
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 635.91us 0.89ms 12.92ms 93.69%
Req/Sec 56.20k 8.07k 62.00k 86.54%
22464657 requests in 30.00s, 17.76GB read
Requests/sec: 748868.53
Transfer/sec: 606.33MB
流量录制及回放
一般针对比较大型的项目,容易出现漏测或者有很多没评估到的地方,如果用线上流量做一次回归测试,可以进一步减少 bug 的风险,同时大大节省构造测试数据的时间,提高测试效率。
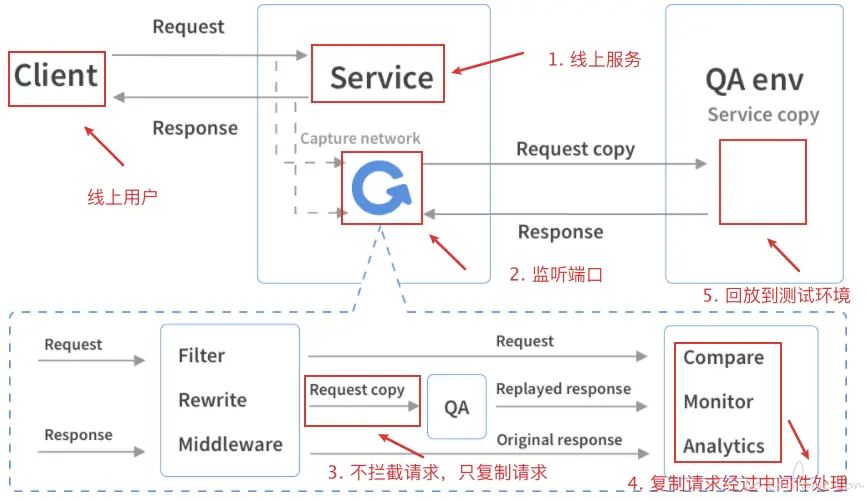
一般流量回放只回放 get 请求,因为其他请求可能会对用户数据进行操作,有风险需要排除掉。
API 网关
网关的作用
摘自知乎。假设你正在开发一个电商网站,那么这里会涉及到很多后端的微服务,比如会员、商品、推荐服务等等。那么这里就会遇到一个问题,APP/Browser 怎么去访问这些后端的服务? 如果业务比较简单的话,可以给每个业务都分配一个独立的域名(如 service.api.company.com),但这种方式会有几个问题:
- 每个业务都会需要鉴权、限流、权限校验等逻辑,需要进行剥离
- 比如淘宝、亚马逊打开一个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,另一方面是连接数的瓶颈。而且每上线一个新的服务,都需要运维参与,申请域名、配置 Nginx 等,当上线、下线服务器时,同样也需要运维参与,另外采用域名这种方式,对于环境的隔离也不太友好,调用者需要根据域名自己进行判断。
- 后端每个微服务可能是由不同语言编写的、采用了不同的协议,比如 HTTP、Dubbo、GRPC 等,但是你不可能要求客户端去适配这么多种协议,这是一项非常有挑战的工作,项目会变的非常复杂且很难维护。后期如果需要对微服务进行重构的话,也会变的非常麻烦,需要客户端配合你一起进行改造,比如商品服务,随着业务变的越来越复杂,后期需要进行拆分成多个微服务,这个时候对外提供的服务也需要拆分成多个,同时需要客户端配合你进行改造,非常蛋疼。
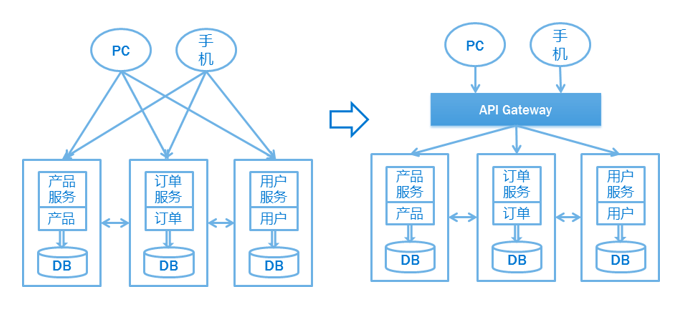
因此可以实现一个 API 网关(API Gateway)接管所有的入口流量,类似 Nginx 的作用,将所有用户的请求转发给后端的服务器,但网关做的不仅仅只是简单的转发,也会针对流量做一些扩展,比如鉴权、限流、权限、熔断、协议转换、错误码统一、缓存、日志、监控、告警等,这样将通用的逻辑抽出来,由网关统一去做,业务方也能够更专注于业务逻辑,提升迭代的效率。通过引入 API 网关,客户端只需要与 API 网关交互,而不用与各个业务方的接口分别通讯。
服务调用方(内部和外部)同时通过 nginx 和 API 网关访问服务提供方示意图如下:
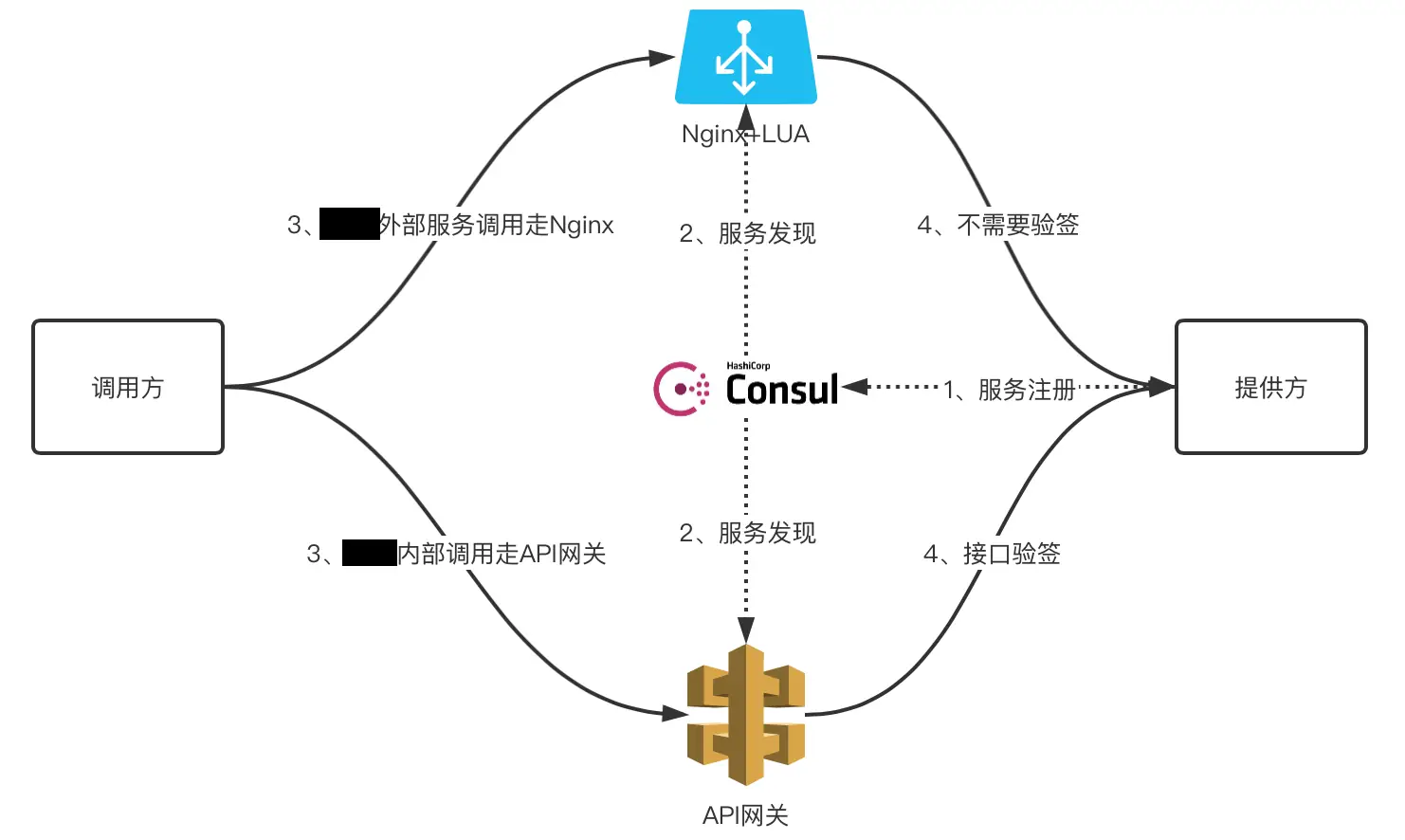
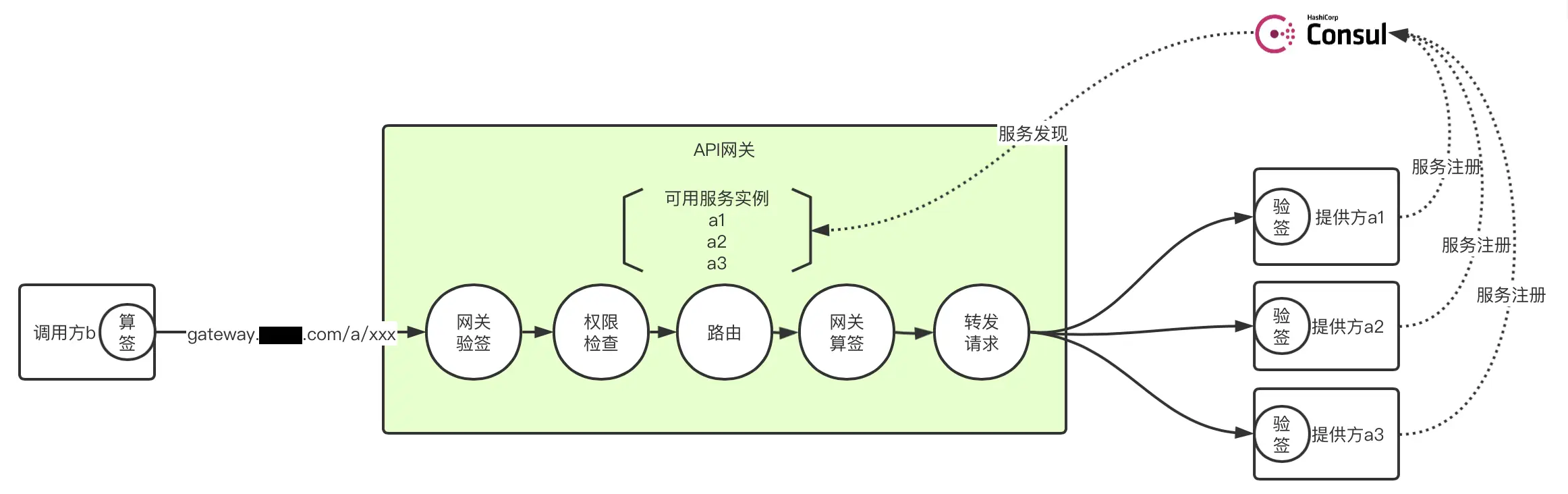
调用方到提供方经过 API 网关的整个链路的各个环节示意图如下:
consul 服务发现
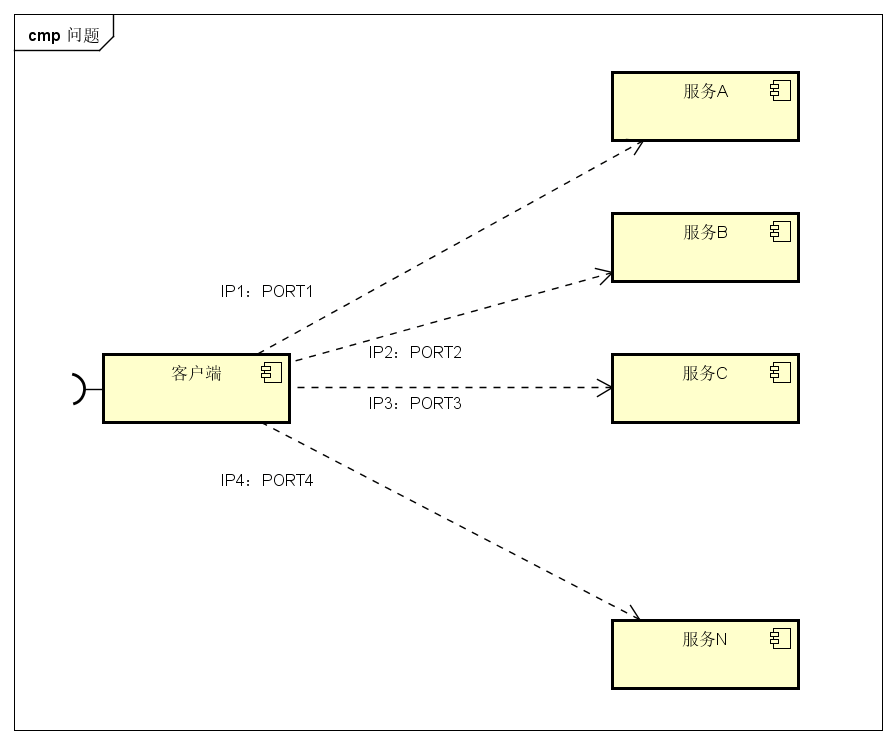
参考这里。微服务的框架体系中,服务发现是不能不提的一个模块。我们看看以前的方案。客户端的一个接口,需要调用服务 A-N。客户端必须要知道所有服务的网络位置的,以往的做法是配置是配置文件中,或者有些配置在数据库中。这里就带出几个问题:
- 需要配置 N 个服务的网络位置,加大配置的复杂性
- 服务的网络位置变化,都需要改变每个调用者的配置
- 集群的情况下,难以做负载(反向代理的方式除外)
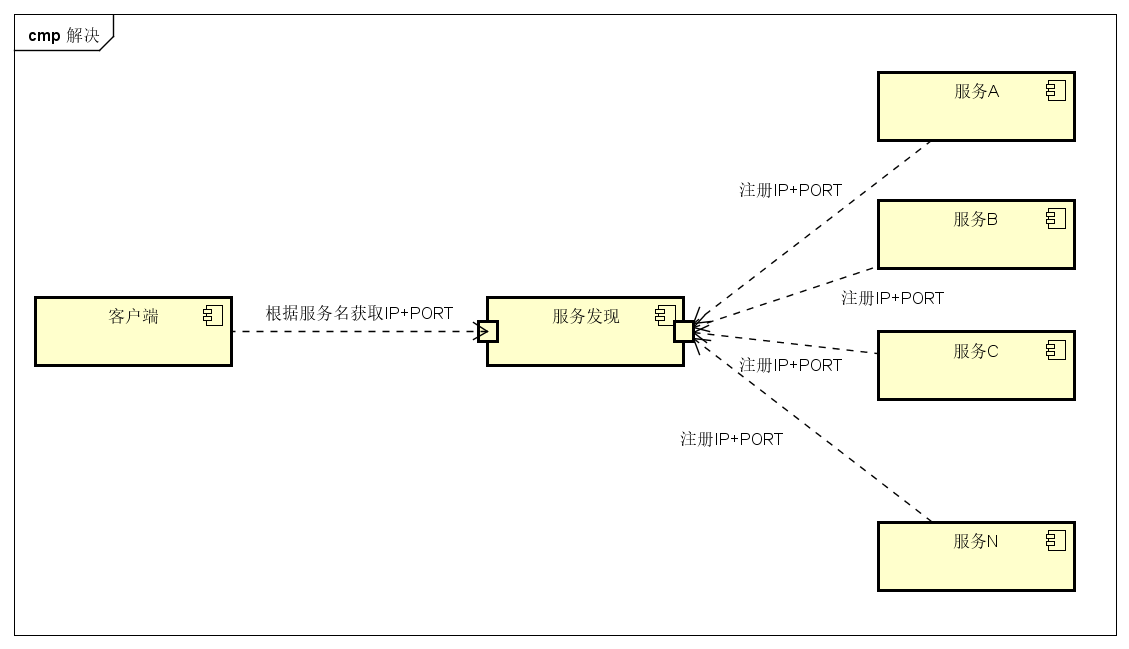
我们再对比下加了服务发现的效果。服务 A-N 把当前自己的网络位置注册到服务发现模块,服务发现就以 K-V 的方式记录下,K 一般是服务名,V 就是 IP:PORT。服务发现模块会定时轮询查看这些服务是否能够正常访问(健康检查)。客户端在调用服务 A-N 的时候,就跑去服务发现模块问下它们的网络位置,然后再调用它们的服务。客户端完全不需要记录这些服务网络位置,客户端和服务端完全解耦!
做服务发现的框架除了 consul 外,常用的还有 zookeeper、eureka、etcd 等。
以下是 consul 的 ui 界面:

蓝绿部署、滚动发布和灰度发布
此部分可参考知乎
蓝绿部署是一种应用发布模式,可将用户流量从旧版本的应用或微服务逐渐转移到几乎相同的新版本中,旧版本可以称为蓝色环境,而新版本则可称为绿色环境。
蓝色环境可以用来做发布前测试,测试过程中发现任何问题,可以直接在蓝色环境上修改,不干扰用户正在使用的系统。确定达到上线标准之后,直接将用户切换到蓝色环境, 切换后的一段时间内,依旧是蓝绿两套环境并存,但是用户访问的已经是蓝色环境。这段时间内观察蓝色环境(新系统)工作状态,如果出现问题,直接切换回绿色环境。
当确信对外提供服务的蓝色环境工作正常,不对外提供服务的绿色环境已经不再需要的时候,蓝色环境正式成为对外提供服务系统,成为新的绿色环境。原先的绿色环境可以销毁,将资源释放出来,用于部署下一个蓝色环境。
比如需要上线一个游戏,没必要等到大半夜人少的时候去更新,而是可以使用蓝绿部署模式在用户使用的高峰期更新应用。这一切都可以不中断服务地完成。蓝绿部署的目的是减少发布时的中断时间、能够快速撤回发布
滚动发布一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。这种部署方式相对于蓝绿部署,更加节约资源 —— 它不需要运行两个集群、两倍的实例数。我们可以部分部署,例如每次只取出集群的 20% 进行升级。但是缺点是回滚困难。而且因为是逐步更新,那么我们在上线代码的时候,就会短暂出现新老版本不一致的情况,如果对上线要求较高的场景,那么就需要考虑如何做好兼容的问题。
灰度发布, 也叫金丝雀发布。让一部分用户继续用 A,一部分用户开始用 B,如果用户对 B 没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到 B 上面来。这种表现形式有点像 abt,但 abt 属于效果测试(关注的是转化率、订单情况等),而不是部署策略。
具体到服务器上, 实际操作中还可以做更多控制,譬如说,给最初更新的 10 台服务器设置较低的权重、控制发送给这 10 台服务器的请求数,然后逐渐提高权重、增加请求数。一种平滑过渡的思路, 这个控制叫做“流量切分”。
17 世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱;而当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为“瓦斯检测指标”,以便在危险状况下紧急撤离。
开源许可证对比
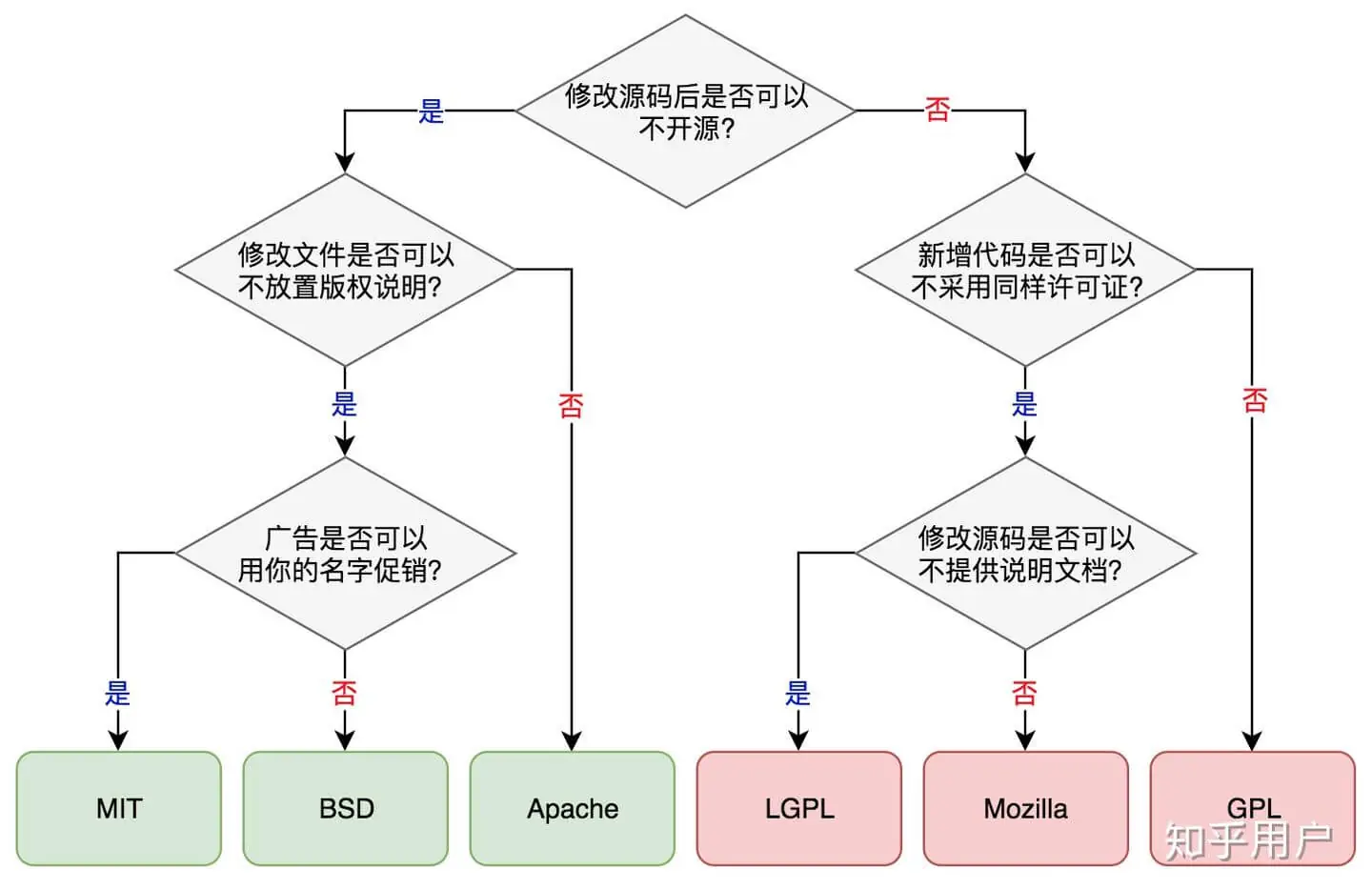
参考链接
- Comparing Virtual Machines vs Docker Containers By Nick Janetakis
- 端口映射和 dmz By 吾心安处方是家
- 录制线上流量做回归测试的正确打开方式 By 少年
- 开放分布式追踪(OpenTracing)入门与 Jaeger 实现 By 吴波bruce_wu