
网络爬虫与反爬
什么是网络爬虫
网络爬虫技术是搜索引擎架构中最为根本的数据技术,通过网络爬虫技术,我们可以将互联网中数以百亿计的网页信息保存到本地,形成一个镜像文件,为整个搜索引擎提供数据支撑。按照系统结构和实现技术,大致可以分为以下几种类型,实际的网络爬虫系统通常是几种爬虫技术相结合实现的:
- 通用网络爬虫(General Purpose Web Crawler)- 也称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据,如 Google、baidu、bing 等
- 聚焦网络爬虫(Focused Web Crawler)- 也称主题爬虫,是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求
- 增量式网络爬虫(Incremental Web Crawler)- 是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫。和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度
- 深层网络爬虫(Deep Web Crawler)- Web 页面按存在方式可以分为表层网页和深层网页。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。例如那些用户注册后内容才可见的网页就属于 Deep Web
网络爬虫是一把双刃剑,我们利用爬虫进行竞品研究分析、营销分析等场景给自身创造价值的同时,也面临着竞争对手、数据提供商等爬虫的侵扰。可能会造成数据泄露或大量爬虫流量占用服务器资源,影响正常用户访问。
基础架构和策略
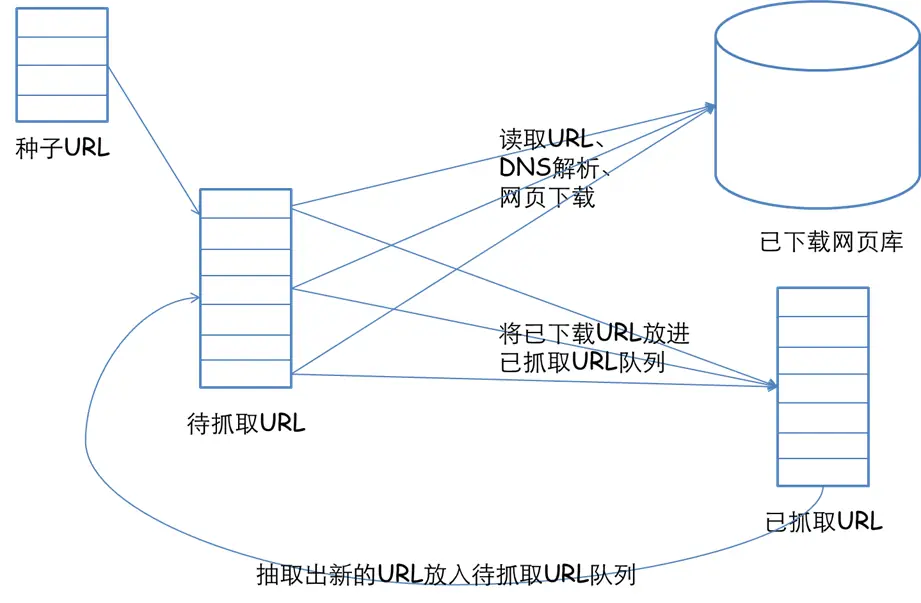
- 根据提供的 URL 列表和相应的优先级,建立待抓取 URL 队列
- 根据待抓取 URL 队列的排序进行网页抓取
- 将获取的网页内容和信息下载到本地的网页库,并建立已抓取 URL 列表
- 将已抓取的网页放入到待抓取的 URL 队列中,进行循环抓取操作
网页的抓取策略可以分为深度优先、广度优先和最佳优先三种。深度优先在很多情况下会导致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法:
- 广度优先 - 广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低
- 最佳优先 - 最佳优先搜索策略按照一定的网页分析算法,预测候选 URL 与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个 URL 进行抓取。它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点
- 深度优先 - 深度优先搜索策略从起始网页开始,选择一个 URL 进入,分析这个网页中的 URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。深度优先策略设计较为简单。然而门户网站提供的链接往往最具价值,PageRank 也很高,但每深入一层,网页价值和 PageRank 都会相应地有所下降
目前比较流行的爬虫框架有 Java 的 Apache Nutch、webmagic 以及 Python 的 Scrapy、Pyspider 等。
反爬虫与反反爬虫
为什么我们要反爬虫,因为爬虫会增加我们页面的 PV,还会一定程度上带来服务器的压力,更何况我们的信息被别人“窃取”,因此反爬道路越走越远。反爬虫策略大致分为两类:
- 以逻辑控制防爬 - 后端,包括设置 IP 访问间隔,限制账号访问次数,账号 IP 组合限制,IP 黑名单,页面 url 加密等
- 设置技术门槛防爬 - 后端加前端,包括图片验证码,图片点击验证,滑动验证,短信验证,cookie 加密,参数加密,js 代码混淆,浏览器 webDriver 识别等
可是既然你针对我爬你,那我就针对你针对我爬你 😲
IP/userAgent 访问限制
反: 一般情况下后台对访问进行统计,如果单个 IP 访问超过阈值,予以封锁,但可能会误封
反反: 可通过使用代理服务器解决。同时,爬虫设置下载延迟,每隔几次请求,切换一下所用代理的 IP 地址
反: 可以针对单个 userAgent 访问超过阈值,予以封锁。这种方法拦截爬虫效果非常明显,但是杀伤力过大,误伤普通用户概率非常高
反反: 收集大量浏览器的 userAgent 或者伪装
页面 url 加密
反: 页面 url 加密是指在多账号情况下网站会根据用户 ID 对其访问的页面进行加密,使每个用户看到的页面 url 不同
反反: 可以将搜索条件拆分到适合单账号访问的大小,并为每个账号分配一个搜索条件或者一些分页,存储的页面 ID 也不能用页面展示的 ID,而是用局部敏感哈希(simhash)生成得到 ID 用于区分各账号是否有重复访问
simhash 离线计算指纹,方便了大规模数据比较时的消耗,不需要在计算时提取特征进行计算,只用对比海明距离即可,方便海量数据去重
图片验证码
反: 各种验证码,是一种区分用户是计算机还是人的公共全自动程序。比如 12306 的识别点触式、bilibili 的拖动滑块等
反反: 简单图片比如数字字母加干扰线的,我们可以通过 Tesseract 来进行 OCR 光学字符识别,其他的可以对接打码平台或者进行模拟等,甚至可以人工打码
比如类似极验这种滑动验证码,总体思路如下,具体可以参考这篇博客:
- 寻找出原图和缺图和缺块
- 如有原图,则对比原图与缺图的坐标像素,相同坐标像素差异明显即偏移距离
- 若只有缺图和缺块,则根据缺图阴影部分特征寻找偏移坐标
- 得到偏移距离后利用数学公式生成坐标移动序列,并用程序按照序列拖动滑块来完成验证
- 若生成的移动序列被识别为非正常操作,可使用穷举法人为拖动滑块并记录坐标移动轨迹
- 遇到相应偏移量的滑块直接取手动生成的轨迹使用,完成验证
# 获取偏移量
def get_gap(self, image1, image2):
"""
获取缺口偏移量
:param image1: 不带缺口图片
:param image2: 带缺口图片
:return:
"""
left = 60
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
# 定义色差阀值
threshold = 70
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
# 构造移动轨迹
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
短信验证码
反: 还有一种场景是短信验证码,我们需要手机来接收,而且一般每一个号码会有次数限制
反: 采用猫池,简而言之就是有通信模块,可收发短信,支持多张手机卡同时使用的硬件设备,并且可以通过管理平台进行统一管理,然后通过代码直接获取接收到的验证码即可
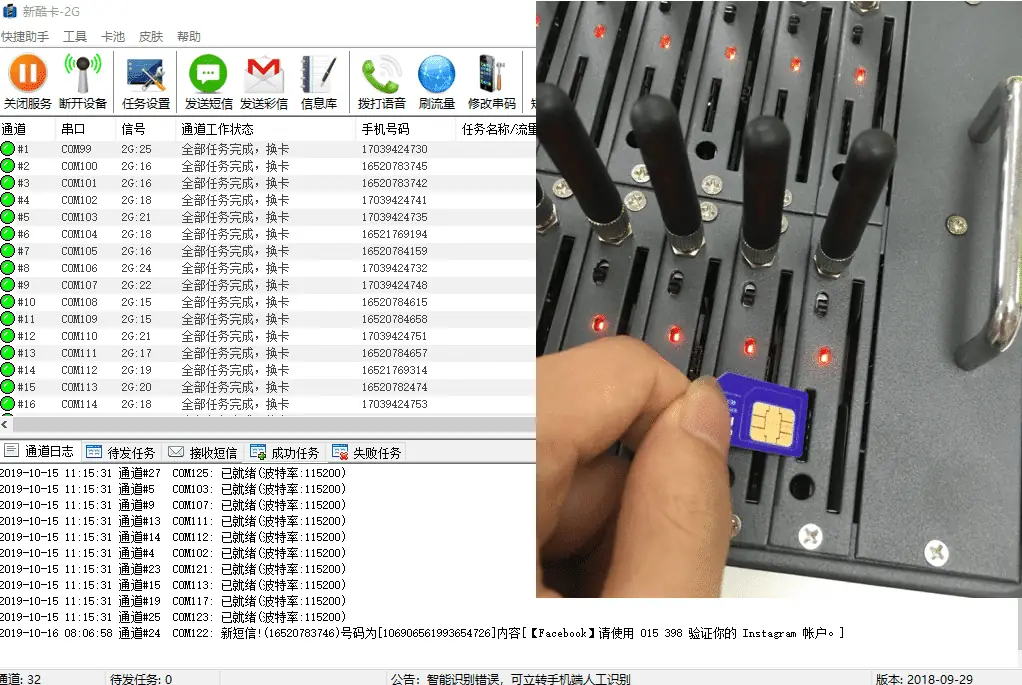
# 通过手机号码取短信
@app.route('/get_code', methods=['GET'])
def get_code():
session = get_mysql_session()
# 当前时间减三分钟
t = (datetime.now() + timedelta(minutes=-3)).strftime("%Y-%m-%d %H:%M:%S")
phone = request.args.get('phone')
kw = request.args.get('keyword')
print(phone, kw)
# 查询三分钟之内接收到的固定手机号包含关键字的短信记录
result = session.query(Message).filter(and_(Message.PhoNum == phone, Message.smsDate > t,
Message.smsContent.like('%{}%'.format(kw))
)).order_by(Message.smsDate.desc()).first()
session.close()
if result:
return result.smsContent
return ''
动态页面
反: 网站页面是动态页面,采用 Ajax 异步加载数据方式来呈现数据
反反: 首先用 Firebug 或者 HttpFox 对网络请求进行分析。直接模拟相应的请求,即可从响应中得到对应的数据。但是如果 ajax 请求参数加密的时候无效,这时候就需要用到 Selenium + PhantomJS 框架来处理,主要是调用浏览器内核,并利用 phantomJS 执行 js 来模拟人为操作以及触发页面中的 js 脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程。利用他们能干很多事情,例如识别点触式(12306)或者滑动式的验证码,对页面表单进行暴力破解等等
Selenium 是一个 Web 的自动化测试工具,可以根据我们的指令模拟用户行为,比如让浏览器自动加载页面,获取需要的数据等。Selenium 本身不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。PhantomJS 是一个基于 Webkit 的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。使用方法可以参考这篇博客 👈
类似 PhantomJS 的还有谷歌的 Puppeteer,主要通过
Chrome DevTools Protocol协议控制Chromium/Chrome浏览器的行为。
cookie 加密
反: 和 Headers 校验的反爬虫机制类似,当用户向目标网站发送请求时,会再请求数据中携带 Cookie,网站通过校验请求信息是否存在 Cookie,以及校验 Cookie 的值来判定发起访问请求的到底是真实的用户还是爬虫
反反: 首先要在对目标网站抓包分析时,必须先清空浏览器的 Cookie,然后在初次访问时,观察浏览器在完成访问的过程中的请求细节。在抓包完成对请求细节的分析之后,再在爬虫上模拟这一转跳过程,然后截取Cookie 作为爬虫自身携带的 Cookie,这样就能够绕过 Cookie 的限制完成对目标网站的访问了
node + cheerio
在我之前博客已经讲过 cheerio 了,具体参考我的这篇博客:
const cheerio = require('cheerio')
const $ = cheerio.load('<h2 class="title">Hello world</h2>')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html() // => <h2 class="title welcome">Hello there!</h2>
关于如何运用 request + cheerio 做网路爬虫的实战后续再补充,先鸽了 咕~咕~
web 反爬案例
需要注意的是,无论做什么反爬,前提是最好不要影响到 SEO。一定要确定 SEO 范围,在 SEO 范围外做策略。
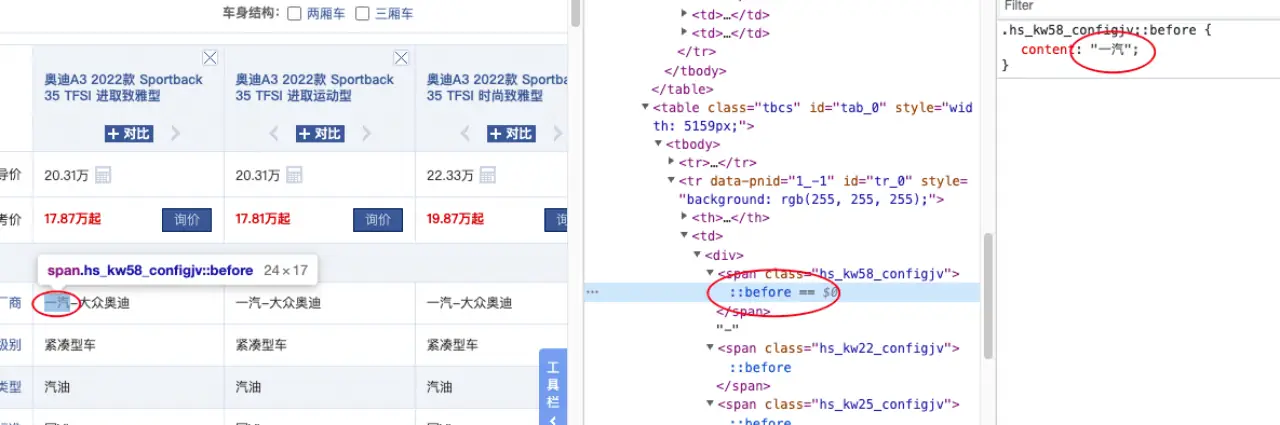
案例一:汽车之家 - 伪元素隐藏
爬取方案:汽车之家里,把关键的厂商信息,做到了伪元素的 content 里。如果我们要提取里面厂商的信息,我们就要解析伪元素的 content
案例二:猫眼电影 - font-face 拼凑式。在我们进入猫眼电影,准备提取某电影的口碑信息、评分信息、票房信息等数据,会发现提取出来的数据不是网页上显示的数据。只有通过他们自定义的font-face 字符集,提取得到的数据进行映射,才能得到真实的数据
爬取方案:
- OCR 识别法 - 获取他们自定义的 font-face 字符集 –> 生成图片 –> 使用 OCR 进行识别 –> 输出映射关系 –> 替换原网页数据
- 字形比对法 - 获取他们自定义的 font-face 字符集作为 base,生成图片,记录每个字形对应的文字信息 –> 发出请求,获取他们自定义的 font-face 字符集 –> 生成图片 –> 和 base 的字形进行比对 –> 最接近的字形作为结果输出 –> 输出映射关系 –> 替换原网页数据

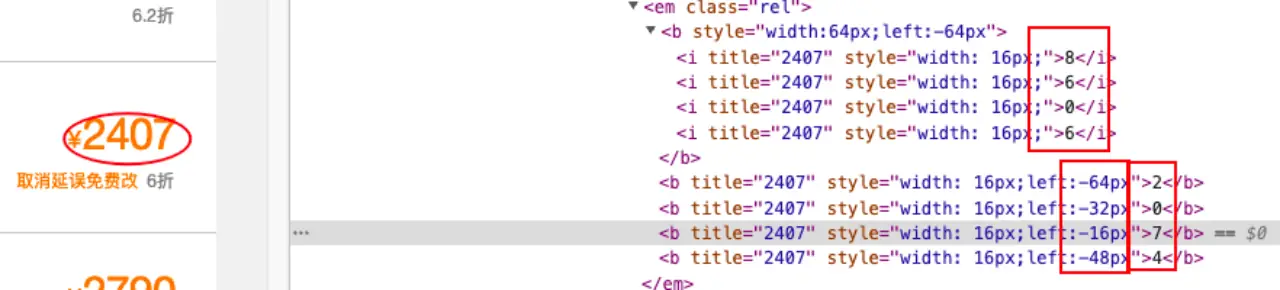
案例三:去哪儿网 - 字体偏移、覆盖。在我们进入去哪儿,准备提取某机票的价格信息数据,会发现提取出来的数据不是网页上显示的数据,在 html 上提取到的数据是 8606 实际数据是 2407,其实他是在下面的两个红色方框做了字体偏移以及字体覆盖
爬取方案:获取他们字体偏移部分的 html 源码 –> 对偏移量进行生序排序 –> 获取真实数据
app 反爬案例
app 和 web 端的反爬有很多区别,主要体现在:
- 开发技术栈不同 - web 端主要使用 JavaScript 技术栈,移动端分为 android 和 ios,其中 android 使用的是 Java 技术栈,核心的加密模块一般使用的是 C 开发,需要掌握汇编和 C 相关底层知识。IOS 生态相对封闭,一般使用的是 ObjectC 开发,需要掌握汇编和 C 相关底层知识。
- 代码获取难度不同 - web 端的代码是完全暴露的,通过浏览器能够很方便获得代码;移动端的代码相对封闭,需要一些反编译工具才能获得源码,部分 app 使用的代码加固的技术,需要一些脱壳的工具才能获得源代码。
- 调试难度不同 - web 端使用浏览器就能够动态调试代码,甚至动态修改变量;移动端的代码动态调试相对复杂,需要借助一些工具,部分 app 对工具做了检查,对抗难度上大大提升。
- 检测点不同 - web 端主要检测浏览器相关信息;移动端检测点很多,涉及到很多底层 android 内核相关检测,检测项主要集中在是否 root、是否被工具调试、是否安装了破解工具、设备的基本信息(手机朝向 / 电量 /wifi/sim 卡)等,检测内容丰富,对抗难度大。
- 账号 - 移动端的 app 一般需要账号登陆,其对于账号的要求会比 web 端严格。
- 风控 - 由于移动端大部分需要账号登陆,并且设备信息容易获取,因此基于账号 / 设备的风控容易实现,在风控方面移动端对比 web 端会严格不少。
要分析 app 第一步工作就是要能够抓到 app 的数据流量包,很多 app 在反抓包上做了很多对抗:
- 检测是否开启了代理
- 对 ssl 证书进行校验
- 使用自研的通信协议
而为了对抗爬虫团队破解 app,一般移动端应用会对应用进行一些加固 / 反调试的措施。
- 加固是指应用对源代码进行了一些反编译上的对抗。一般的 android apk 其实就是一个 zip 包,解包工具能够直接拿到源代码,简单反编译后就能看到代码逻辑。而使用加固工具后,核心代码隐藏在一些二进制文件中,只有当 apk 启动运行时,会动态的对这些二进制文件进行解密,加载到内存,app 才能正常运行。逆向工程师在进行加固对抗的时候,必须知道这些核心代码是什么时机进行加载的,如何进行加解密,才能还原出真实代码。
- 反调试是指应用对一些破解 / 反调试工具上的对抗。逆向工程师在破解 app 的时候,需要借助一些破解工具才能更好理解代码的逻辑,而 app 在被这些工具调试时,进程信息、设备环境则会与真实环境不同,反调试对抗则会对这些点进行检测,如果发现会进入到错误的代码逻辑甚至终止破解工具的使用。另外,有些反调试对抗会针对破解工具的反编译逻辑,让反编译工具在反编译时报错。
风控分为设备检测和行为风控:
设备检测是指 app 利用一些获取设备信息的手段,检测设备的运行环境是否安全。一般而言,对于设备检测发现的风险点,app 并不一定会粗暴的无法使用,而是会上报相关信息,降低设备 / 账号的安全等级,为后续风控对抗提供参考。常见的检测有:
- 设备是否 root / 越狱,由于很多逆向工具的使用都是基于 root / 越狱为前提,检测是否 root / 越狱能很大程度发现安全风险,目前基本所有金融 app 对 root / 越狱都做了检测,一旦发现 app 就无法正常运行。
- 设备基本信息,例如设备的基本信息(厂商、型号等参数)、设备的品牌、主板、串码等硬件信息,通过这些基本信息与安全厂商的设备数据库进行对比,就能够知道设备是否是真实设备,例如一台小米 10,用的是晓龙 870 的芯片、某个芯片的编码是以 012 开头的,逆向工程师如果随机了这些芯片编码,与设备数据库不符合,则会被标记为高危。
- 设备的一些动态信息,例如设备陀螺仪、设备 GPS、设备电量。这些信息也能帮助识别设备的风险,例如一台手机,长期电量维持不变、手机朝向不变、那可能就会被认为是一台被群控设备的手机。
- 设备应用列表,一般用户都会安装很多常用应用,例如微信、支付宝等,如果一台手机的应用列表里应用过少、或是没安装常用应用,则会被标记为高危。
- 逆向工具的检测,一般设备会对逆向工具进行检测,例如是否存在 xx 名字的进程名,某些端口是否被应用占用,某些路径下是否存在某文件,一旦被检测到,设备的安全等级也会被降低。
行为风控主要是 app 会根据用户具体的一些访问行为做日志分析。app 的抓包分析经常发现大厂的 app 会定时访问一些 x.gif 文件,这就是一个典型的用户行为日志上报,app 会实时获取用户的访问行为、点击轨迹、设备信息等数据上报到风控接口,风控接口拿到这些日志数据后,就会结合一些算法的能力对访问行为做聚类分析,分析出异常流量。
此外,对常规的访问行为,每次访问的请求头、IP、跳转记录等也会被记录并进行分析,正常的用户获取某个商详往往有明确的路径,可能是从首页 / 店铺页进入访问的,而爬虫则会频繁访问某一类页面,与真实行为不符。这部分对抗难度主要体现在爬虫除了模拟想要的请求,还需要模拟日志的上报,还需要设计模拟出一套合理的访问路径,难度极大。
参考链接
- 搜索引擎知识
- 搜索引擎技术之网络爬虫 By Poll的笔记
- 爬虫与反爬虫的博弈 By 猴哥
- 关于反爬虫,看这一篇就够了 By ctriptech
- 反爬必修课之—-(1)图像验证码识别 By 興華的mark